.jpg)
人工知能(AI)やAI搭載アプリケーションが年々成長するにつれて、インターネット・プライバシーの重要性はますます高まっています。しかし、分散型オニオンルーティングネットワークである「Anyone Network」のようなプライバシー技術と統合することで、ユーザーは安全かつ匿名でAIを構築することができます。
Anyone Protocolチームによるこのゲストブログ記事では、Aethirの分散型GPUクラウドユニットをどのように構成すれば匿名でコンテンツを提供できるかを掘り下げ、既存のGPUプロバイダーに対するパフォーマンスを評価します。
さあ、見ていきましょう!
エグゼクティブ・サマリー
コラボレーション
AnyoneはAethirと協力し、GPUのパフォーマンスとスケーラビリティ(拡張性)に重点を置いて、AethirのAI GPUクラウドインフラストラクチャを評価しました。この技術レビューの範囲は、AIワークロードにおけるGPU機能のベンチマークに重点を置いており、Telegramプラットフォーム内に展開された実用的なAI搭載ユーティリティボットの開発によって補完されています。
結果を提示する前に、一般的な中小企業(SMB)のインフラニーズと、単一のAethir GPUクラウドユニットが提供する機能との比較概要から始めます。これにより、実際のAIアプリケーションにおける費用対効果、スケーラビリティ、パフォーマンスを評価するための背景が設定されます。
アーキテクチャ
クラウドサーバーの仕様
モデル: RTX 5090 × 2
CPU: AMD Ryzen 9 7900X 12-Core Processor
RAM: 64 GiB
ストレージ: 2TB
ネットワーキング: 10Gb
GPU電力: 575W
OS: Ubuntu 22.04.1-Ubuntu
オンプレミスサーバーの仕様
モデル: RTX 4090
CPU: 13th Gen Intel(R) Core(TM) i9-13900KS
RAM: 64 GiB
ストレージ: 2TB
ネットワーキング: 1Gb
GPU電力: 450W
OS: Kernel 6.17.2-arch1-1
ソフトウェア・アーキテクチャ
クラウド構成とオンプレミス構成の両方で、同じソフトウェア構成を採用しています。主な違いはGPUです。ベンチマークのアーキテクチャは以下のように定義されています:
フロントエンド: Telegram Bot(ユーザーインターフェース)
バックエンド: ComfyUIと統合されたpython-telegram-bot
データベース: PostgreSQL(状態管理およびユーザーセッション追跡)
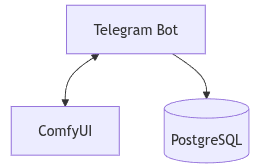
システムワークフロー
私たちのアーキテクチャでは、ユーザーの対話はTelegramから始まり、ボットがコマンドインターフェースとして機能します。各ユーザーのクエリはボットによって解析(パース)され、GPU上で実際の推論を実行するComfyUIへのタスクに変換されます。
システムは以下のように機能します:
- ユーザーがTelegram経由でコマンドを送信する。
- Telegramボット(python-telegram-botを使用して構築)がコマンドを受信し、解析する。
- ボットは処理のためにタスクをComfyUIに送信する。
- ComfyUIは適切なモデルを使用して推論を実行し、出力(画像など)を返す。
- 出力はTelegramチャットを通じてユーザーに返送される。
- PostgreSQLは、ユーザーセッション、ジョブキュー、およびユーザーコマンドとモデルワークフロー間のマッピングを管理する。
この構造により、データベースを通じた永続的なコンテキストを持つステートレスな推論が可能になり、スケーラブルで、シングルユーザーおよびマルチユーザーの両方のシナリオに適したものとなります。
ボットの例

ボットコマンドの例(/f は flux用)
このコマンドは、テキストから画像へのプロンプト(指示)をComfyUIに送信します。ボットはリクエストを処理し、画像が生成されるのを待ってから、以下の結果に示すように、結果の画像をTelegramチャットでユーザーに直接返信します。
画像(例:宇宙飛行士、Tシャツ)が生成されると、ユーザーは追加のコマンドを使用してさらに構築を行うことができます。例えば、「/qwen」コマンドと連鎖させて、宇宙飛行士にTシャツを着せるように依頼することができます。
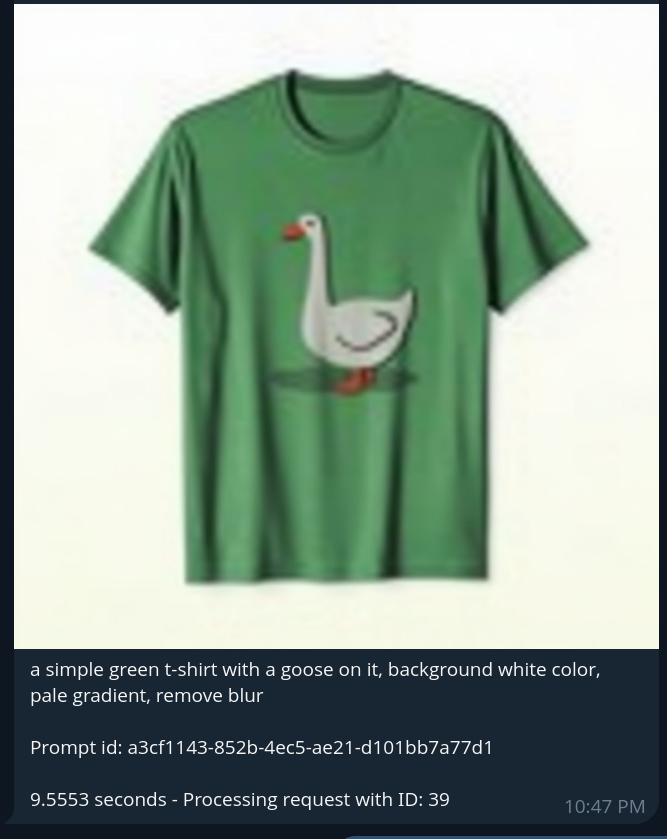

これはQwenモデルのワークフローを呼び出し、前の画像とテキストによる指示を入力として使用して画像編集を実行します。結果の画像は、修正が適用された状態(例:ガチョウのTシャツを着た宇宙飛行士)でTelegram経由で返されます。このコマンド連鎖機能により、軽量なチャットインターフェース内から、対話的でマルチステップな画像生成と編集が可能になります。
エンドポイント
すべてのComfyUIエンドポイントはルート経由で公開されており、公式サーバーガイドに詳細が記載されています。
https://docs.comfy.org/development/comfyui-server/comms_routes
これらのエンドポイントは、バックエンドとComfyUI間の通信のバックボーンを形成し、プロンプトの送信、迅速なキュー管理、メディアのアップロードとダウンロード、およびリアルタイムフィードバックを可能にします。
以下は、統合に関連する主要なエンドポイントです:
/ws websocket サーバーとのリアルタイム通信用エンドポイント
/upload /image post 画像のアップロード
/prompt get 現在のキューステータスと実行情報の取得
/prompt post キューへのプロンプト送信
/queue get 実行キューの現在の状態の取得
/queue post キュー操作の管理(保留中/実行中のクリア)
これらのエンドポイントはバックエンドを通じてプログラム的にアクセスされ、Telegramボットによって調整されるため、ユーザーがAPIと直接やり取りすることなく、インタラクティブなユーザー体験が促進されます。
プライバシー
ユーザーデータを保護し、安全な送信を確保し、情報のプライバシーを維持するために、ComfyUIのエンドポイントはAnyone Networkを通じてルーティングされます。この統合は、Anyone ProtocolのGitHubで提供されている公式Python SDKを使用して可能になります。
https://github.com/anyone-protocol/python-sdk
この開発キットを使用することで、ComfyUIのAPI呼び出しを安全で匿名のトンネル内にラップ(包摂)することができ、ユーザーのクエリや生成されたメディアが不正なアクセスや漏洩から保護されることを保証します。
Anyoneアーキテクチャ:Anonと呼ばれるバイナリでエンドポイントをラップ

暗号化されたトンネリングに加えて、Anyone SDKは**Hidden Services(秘匿サービス)**をサポートしています。Hidden Servicesは、場所、身元、IPを明かすことなく実行できるプライベートで一時的なサーバーエンドポイントです。これらは、慎重さ、検閲耐性、または強化されたセキュリティが重要となるユースケースで特に価値があります。オペレーターにとって、Hidden Servicesはインフラの詳細を公開することなく、GPUタスクをプライベートに実行することを可能にします。推論パイプラインを匿名で構成する場合でも、機密データで共同作業する場合でも、単に痕跡を残さずに実験する場合でも、Hidden Servicesは安全で主権のあるコンピュートの新たな可能性を切り開きます。
Hidden Serviceは次のようになります:
🌐 http://5ugakqk324gbzcsgql2opx67n5jisaqkc2mbglrodqprak5qz53mibyd.anon
🌐 http://5ugakqk324gbzcsgql2opx67n5jisaqkc2mbglrodqprak5qz53mibyd.anyone
Hidden Servicesは、ウェブプラットフォームの場合はフロントエンド用に構成することも、ComfyUIのバックエンドエンドポイント用に構成してパイプライン全体を保護することも可能です。
Hidden Servicesの詳細については、Anyoneのドキュメントを参照してください。
https://docs.anyone.io/sdk-integrations/native-sdk/tutorials
ベンチマーク
以下のベンチマークは、一連のComfyUIワークフローとモデルにおけるRTX 4090とRTX 5090のパフォーマンスを比較したものです。公平な比較を確実にするため、すべてのテストは一貫した設定とテンプレートを使用して実施されました。
Stable Diffusion 3
ComfyUIテンプレート: sd3.5_simple_example
4090: 8.96秒(平均)
5090: 5.96秒(平均)
スピードアップ = 33.48%
ワークフロー:
RTX 5090はこのテストで4090より約33%高速であり、ComfyUIにおけるStable Diffusion 3.5ワークフローに対して確実なパフォーマンス向上を提供します。
FLUX-SCHNELL
ComfyUIテンプレート: flux_schnell_full_text_to_image
4090: 4.92秒
5090: 1.80秒
スピードアップ = ~63.41%
ワークフロー:
RTX 5090はこのテストで4090より約63%高速であり、Flux Schnellモデルを使用したテキストから画像へのワークフローに対して大幅なパフォーマンス改善を提供します。
FLUX-DEV
ComfyUIテンプレート: N/A(カスタムFlux Devテストテンプレート)
4090: 16.05秒
5090: 10.11秒
スピードアップ = ~37.01%
ワークフロー:
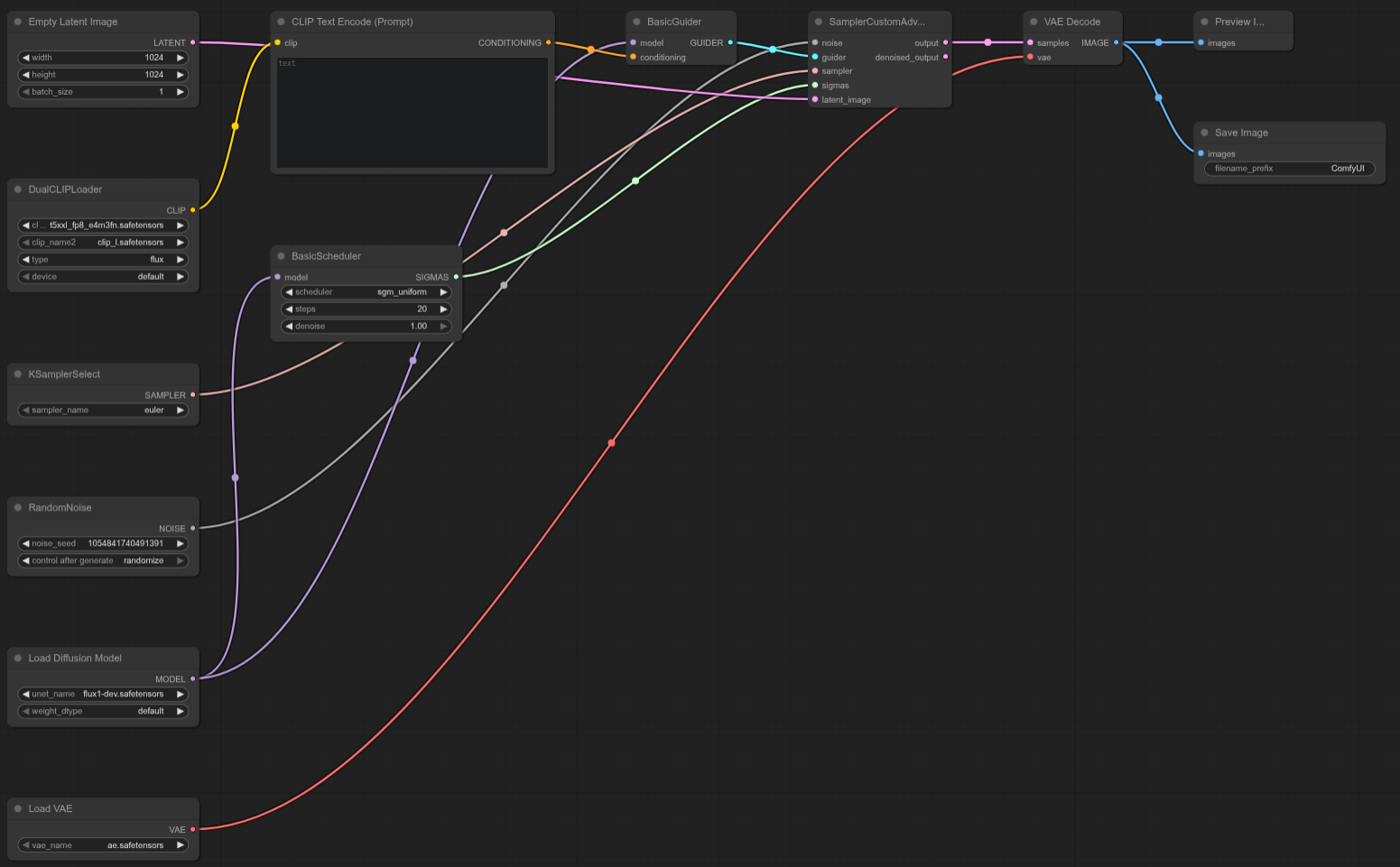
RTX 5090はこのカスタムFlux Devテストで4090より約37%高速であり、この特定のワークフローに対して強力なパフォーマンス向上をもたらします。
WAN 2.2
ComfyUIテンプレート: video_wan2_2_14B_t2v (fp8 scaled + 4 steps LoRA)
4090: 61.87秒
5090: 37.15秒
スピードアップ = ~39.94%
ワークフロー:
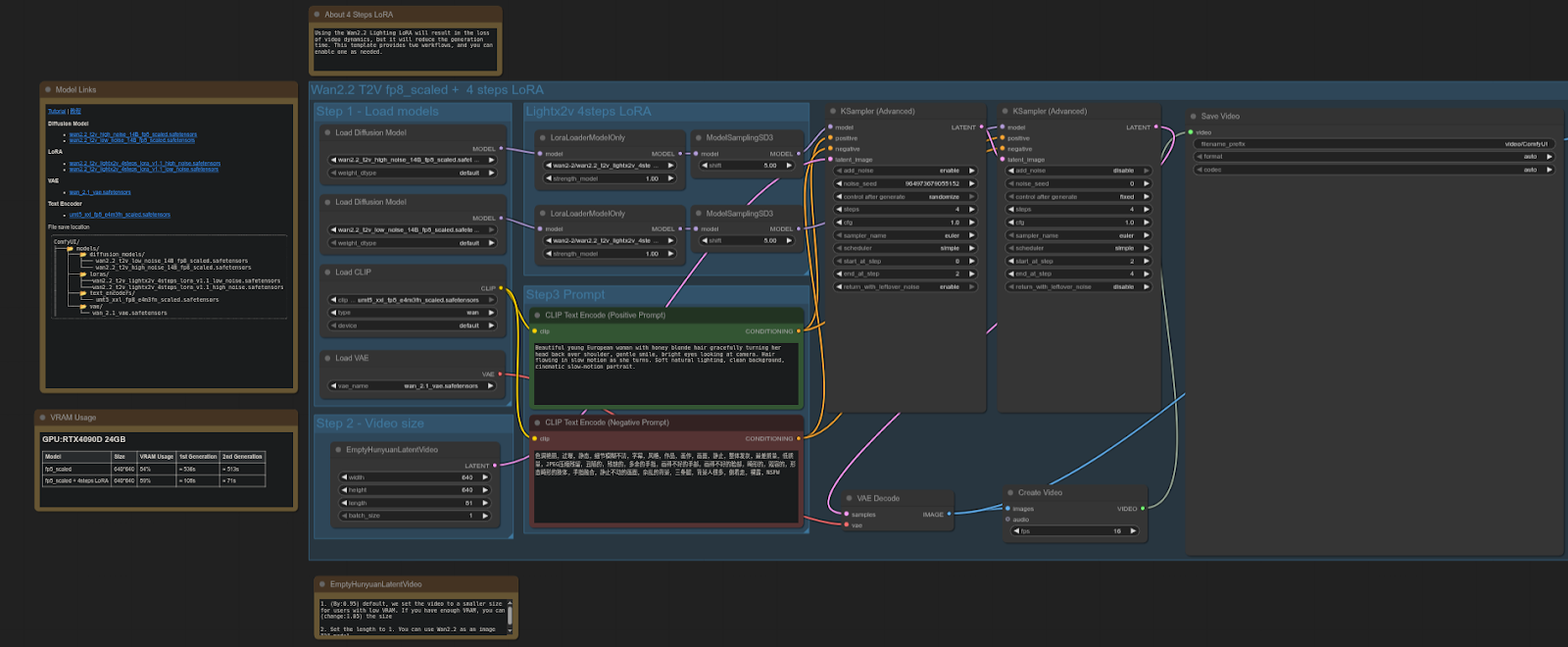
RTX 5090はこのテストで4090より約40%高速であり、FP8スケールモデル + LoRAを使用したビデオ拡散ワークフローにおいて大きなパフォーマンス向上となります。
QWEN
ComfyUIテンプレート: image_qwen_image_edit_2509
4090: 9.62秒
5090: 4.44秒
スピードアップ = ~53.83%
ワークフロー:
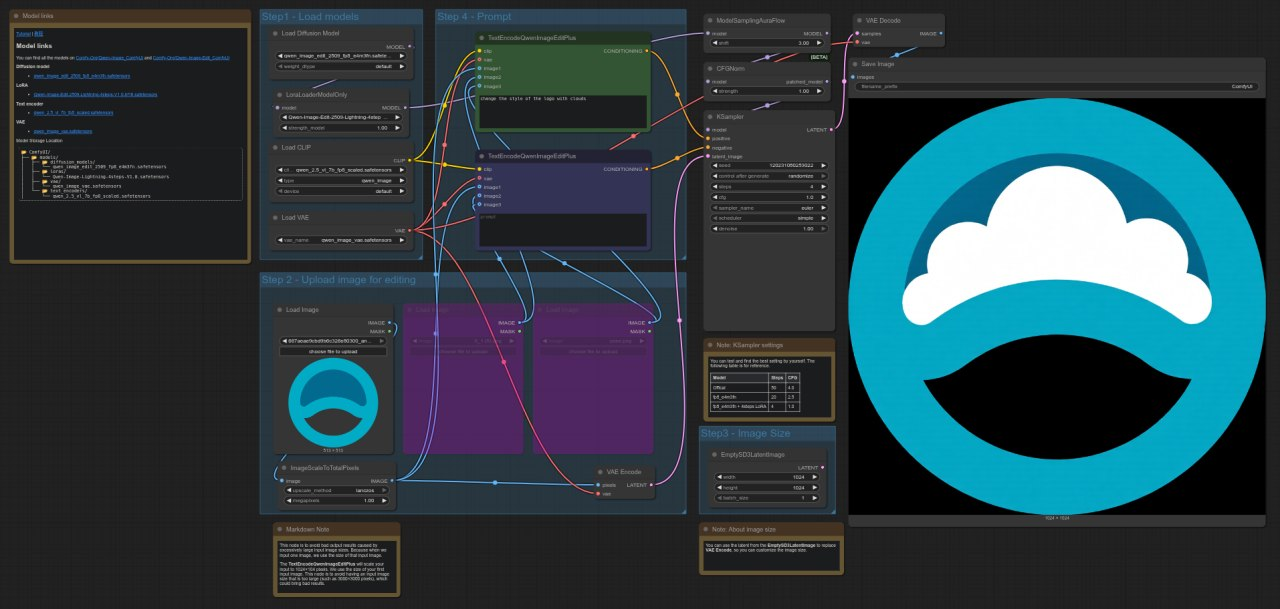
RTX 5090はこのテストで4090より約54%高速であり、Qwenモデルを使用した画像編集ワークフローに対して顕著なパフォーマンス改善を示しています。
エクストラ(追記)
サーバーには2つのGPUが搭載されているため、プログラム的にワークロードを分散させることが可能です。これは、各ノードに特定のCUDAデバイスを定義することで実現でき、タスクを両方のGPUに分割することができます。以下のリポジトリは、ノードを異なるCUDAデバイスに割り当てることで、マルチGPUセットアップ用にComfyUIを構成する方法を示しています:
https://github.com/pollockjj/ComfyUI-MultiGPU

Anyone Protocolの簡単な紹介
Anyoneは、プライバシーのための分散型グローバルインフラストラクチャです。彼らのオニオンルーティングネットワークと統合することで、アプリはユーザー体験を変えることなく、トラストレス(信頼不要)なプライバシーを提供し、ネットワークトラフィックを保護することができます。ネットワークは、トークン報酬と引き換えに帯域幅を提供する数千のノードで構成されています。 - https://www.anyone.io



.jpg)
.jpg)