.jpg)
Como la inteligencia artificial, las aplicaciones impulsadas por internet crecen año tras año y la privacidad se vuelve cada vez más importante. Pero al integrarse con tecnología de privacidad como la Red de Anyone- una red de enrutamiento descentralizada: los usuarios pueden construir sobre ella de forma segura y anónima.
En esta publicación de blog invitada por Protocolo Anyone, profundizamos en cómo se puede configurar una unidad de nube GPU descentralizada Aethir para servir contenido de forma anónima y evaluamos su rendimiento en comparación con los proveedores de GPU existentes.
¡Vamos a sumergirnos!
Resumen ejecutivo
Colaboración
Anyone colaboró con Aethir para evaluar su infraestructura de nube de GPU con IA, con énfasis en el rendimiento y la escalabilidad de la GPU. El objetivo de esta revisión técnica es evaluar las capacidades de la GPU en cargas de trabajo de IA, complementado con el desarrollo de un bot de utilidad práctico basado en IA, implementado en la plataforma Telegram.
Antes de presentar los resultados, comenzamos con una descripción general que compara las necesidades de infraestructura de una pequeña y mediana empresa (PYME) típica con las capacidades que ofrece una sola unidad de nube GPU Aethir. Esto establece el contexto para evaluar la rentabilidad, la escalabilidad y el rendimiento en aplicaciones de IA del mundo real.
Arquitectura
Especificaciones del servidor en la nube
Modelo:RTX 5090×2
UPC Procesador AMD Ryzen 9 7900X de 12 núcleos
RAM:64 GiB
Almacenamiento:2 TB
Redes:10 GB
Potencia de la GPU575W
Sistema operativo: Ubuntu 22.04.1-Ubuntu
Especificaciones del servidor local
Modelo:RTX 4090
UPC: Intel(R) Core(TM) i9-13900KS de 13.ª generación
RAM:64 GiB
Almacenamiento:2 TB
Redes: 1 GB
Potencia de la GPU:450W
Sistema operativo: Núcleo 6.17.2-arch1-1
Arquitectura de software
Tanto las configuraciones de servidor en la nube como las locales utilizan la misma configuración de software. La principal diferencia radica en la GPU y la arquitectura de referencia se ha definido como:
Interfaz: Bot de Telegram (interfaz de usuario)
Parte trasera: python-telegram-bot integrado con Interfaz de usuario cómoda
Base de datos: PostgreSQL (gestión de estados y seguimiento de sesiones de usuario)
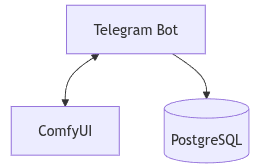
Flujo de trabajo del sistema
En nuestra arquitectura, la interacción del usuario comienza en Telegram, donde el bot actúa como interfaz de comandos. Cada consulta del usuario es analizada por el bot y traducida en una tarea para Interfaz de usuario cómoda, que realiza la inferencia real sobre el GPU.
El sistema funciona de la siguiente manera:
1. El usuario envía un comando a través de Telegram
2. El bot de Telegram (creado con python-telegram-bot) recibe y analiza el comando
3. El bot envía la tarea a ComfyUI para su procesamiento.
4. ComfyUI realiza la inferencia utilizando el modelo apropiado y devuelve un resultado (por ejemplo, una imagen).
5. La salida se envía de vuelta al usuario a través del chat de Telegram.
6. PostgreSQL sirve para administrar sesiones de usuario, colas de trabajos y el mapeo entre comandos de usuario y flujos de trabajo del modelo.
Esta estructura permite inferencia sin estado con contexto persistente a través de la base de datos, haciéndola escalable y adecuada tanto para escenarios de usuario único como de múltiples usuarios.
Ejemplo de bot

Ejemplo de comando de bot (/f para flux)
Este comando envía un texto a imagen aviso aI nterfaz de usuario y el El bot procesa la solicitud, espera a que se genere la imagen y envía la imagen resultante directamente en el Telegram Chatea con el usuario como se muestra en el resultado a continuación.
Una vez que se ha generado una imagen (por ejemplo,un astronauta, a camiseta), los usuarios pueden desarrollarlo usando comandos adicionales. Por ejemplo, pueden encadenarlo con el comando "/qwen”comando para pedir que le pongan la camiseta al astronauta:
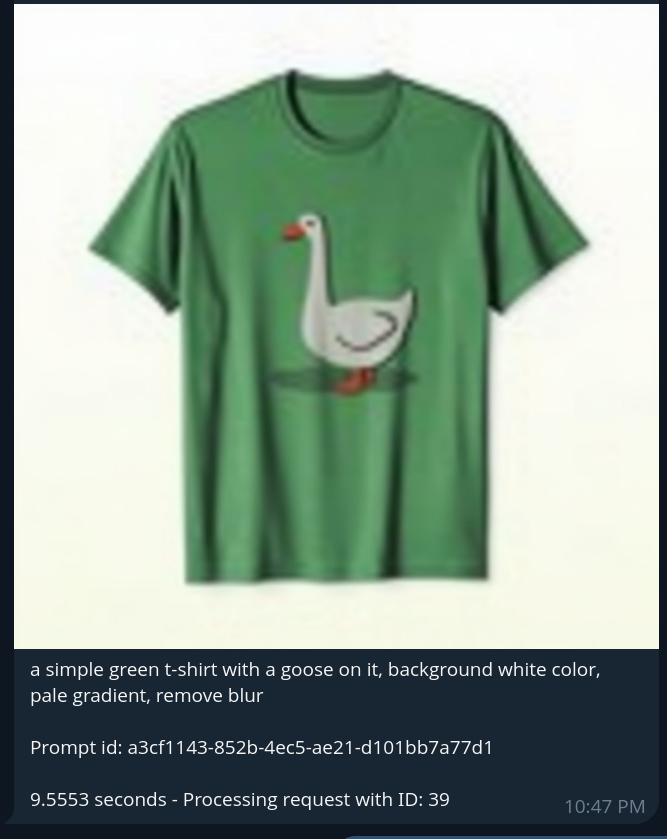

Esto invoca el Qwen Flujo de trabajo del modelo, que realiza la edición de imágenes utilizando una imagen previa como entrada junto con una instrucción textual. La imagen resultante se devuelve mediante Telegram con la modificación aplicada (por ejemplo,El astronauta ahora lleva una camiseta de ganso). Esta capacidad de encadenamiento de comandos permite la generación y edición de imágenes interactivas en varios pasos, todo desde una interfaz de chat liviana.
Puntos finales
Todo Interfaz de usuario cómoda Los puntos finales se exponen a través de rutas y están documentados en detalle en la guía oficial del servidor:
https://docs.comfy.org/development/comfyui-server/comms_routes
Estos puntos finales forman la columna vertebral de la comunicación entre el back end y ComfyUI, lo que permite Envío rápido, gestión rápida de colas, carga y descarga de medios y retroalimentación en tiempo real.
A continuación se presentan los puntos finales clave relevantes para nuestra integración:
/ws WebSocket punto final para la comunicación en tiempo real con el servidor
/subir /imagen correo subir una imagen
/inmediato conseguir recuperar el estado actual de la cola y la información de ejecución
/inmediato correo enviar una solicitud a la cola
/cola conseguir recuperar el estado actual de la cola de ejecución
/cola correo Gestionar operaciones de cola (borrar pendientes/en ejecución)
A estos puntos finales se accede mediante programación a través del back end, orquestado por el Telegram bot para facilitar una experiencia de usuario interactiva sin requerir que los usuarios interactúen directamente con el API.
Privacidad
Para proteger los datos del usuario, asegúrese seguro transmisión y preservar la privacidad de la información, la Interfaz de usuario cómoda Los puntos finales se enrutan a través de la red Either Network. Esta integración es posible gracias al uso de la red oficial SDK de Python proporcionado en el Protocolo Anyone GitHub:
https://github.com/cualquiera-protocolo/python-sdk
Usando este kit de desarrollo, podemos envolver la API de ComfyUI haciendo llamadas dentro seguro,túneles anónimos garantizar que las consultas de los usuarios y los medios generados estén protegidos contra el acceso o la exposición no autorizados.
¿Alguien tiene una arquitectura que envuelva los puntos finales con el binario llamado Anon?:

Además de túnel cifrado, el Cualquier SDK apoya servicios ocultos Los servicios ocultos son privado,puntos finales de servidor efímeros que puede correr sin revelar su ubicación,identidad, o Propiedad intelectual, Estos son particularmente valiosos para casos de uso donde La discreción, la resistencia a la censura o una mayor seguridad son fundamentalesPara los operadores, los servicios ocultos pueden habilitar GPU tareas para ejecutar de forma privada,Sin exponer detalles de infraestructura Ya sea que esté configurando canales de inferencia de forma anónima, colaborando con datos confidenciales o simplemente experimentando sin dejar rastro,Los servicios ocultos abren nuevas posibilidades para una computación segura y soberana.
Un servicio oculto podría verse así:
🌐http://5ugakqk324gbzcsgql2opx67n5jisaqkc2mbglrodqprak5qz53mibyd.anon
🌐http://5ugakqk324gbzcsgql2opx67n5jisaqkc2mbglrodqprak5qz53mibyd.alguien
Servicios ocultos Se puede configurar para el Interfaz, suponiendo que sea una plataforma web en ese caso, o también para ComfyUI parte trasera puntos finales, protegiendo todo el pipeline.
Para obtener más información sobre los servicios ocultos, podemos consultar la documentación de Either:
https://docs.anyone.io/sdk-integrations/sdk-nativo/tutoriales
Puntos de referencia
Los siguientes puntos de referencia comparan el rendimiento deRTX 4090 y RTX 5090 en una gama de Interfaz de usuario cómoda Flujos de trabajo y modelos. Todas las pruebas se realizaron con configuraciones y plantillas consistentes para garantizar una comparación justa.
Difusión estable 3
Plantilla ComfyUI: sd3.5_ejemplo_simple
4090: 8,96 segundos (promedio)
5090: 5,96 segundos (promedio)
Aceleración = 33,48%
Flujo de trabajo:
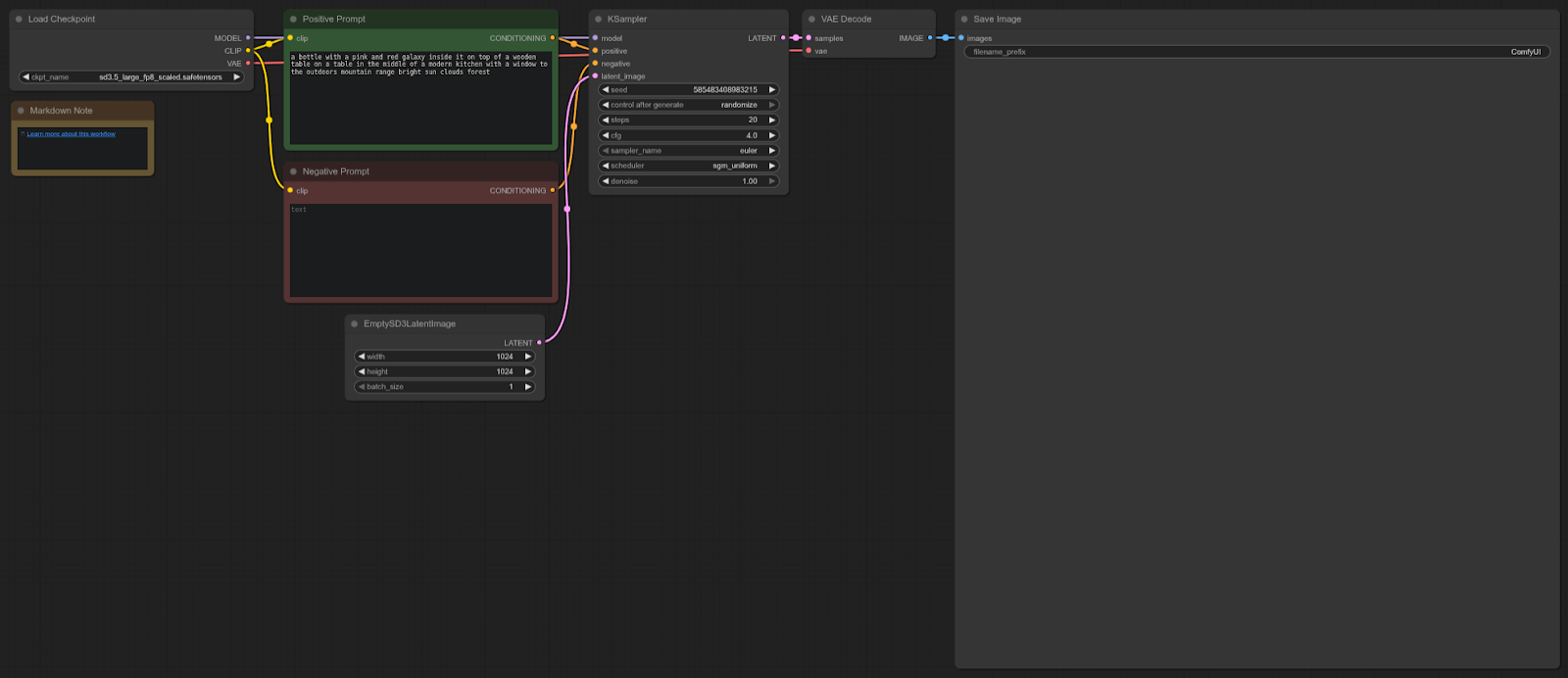
La RTX 5090 es aproximadamente un 33 % más rápida que la 4090 en esta prueba, ofreciendo una mejora sólida del rendimiento para los flujos de trabajo de Stable Diffusion 3.5 en Interfaz de usuario cómoda.
FLUX-SCHNELL
Interfaz de usuario cómoda: Plantilla: flux_schnell_texto completo a imagen
4090: 4,92 segundos
5090: 1,80 segundos
Aceleración = ~63,41%
Flujo de trabajo:
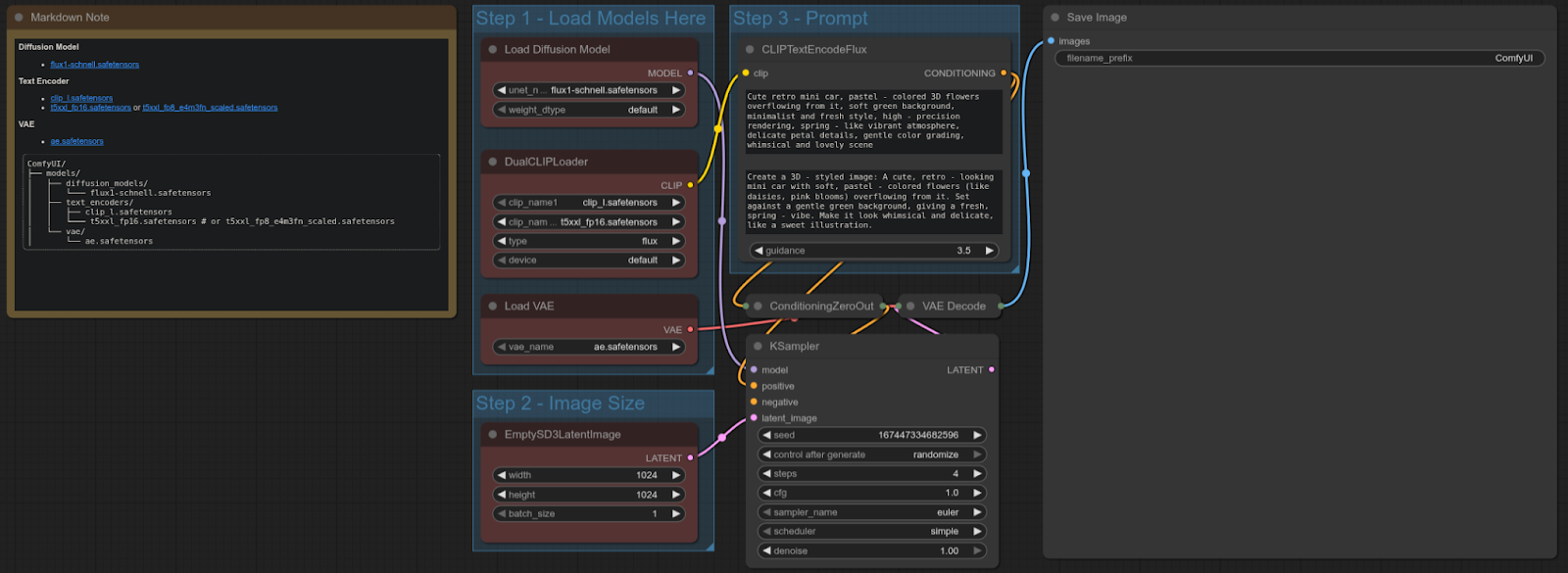
La RTX 5090 es aproximadamente un 63 % más rápida que la 4090 en esta prueba, se proporciona una mejora significativa del rendimiento para los flujos de trabajo de texto a imagen utilizando el modelo Flux Schnell.
FLUX-DEV
Interfaz de usuario cómoda: Plantilla: N/D (Plantilla de prueba de desarrollo de Flux personalizada)
4090: 16,05 segundos
5090: 10,11 segundos
Aceleración = ~37,01%
Flujo de trabajo:
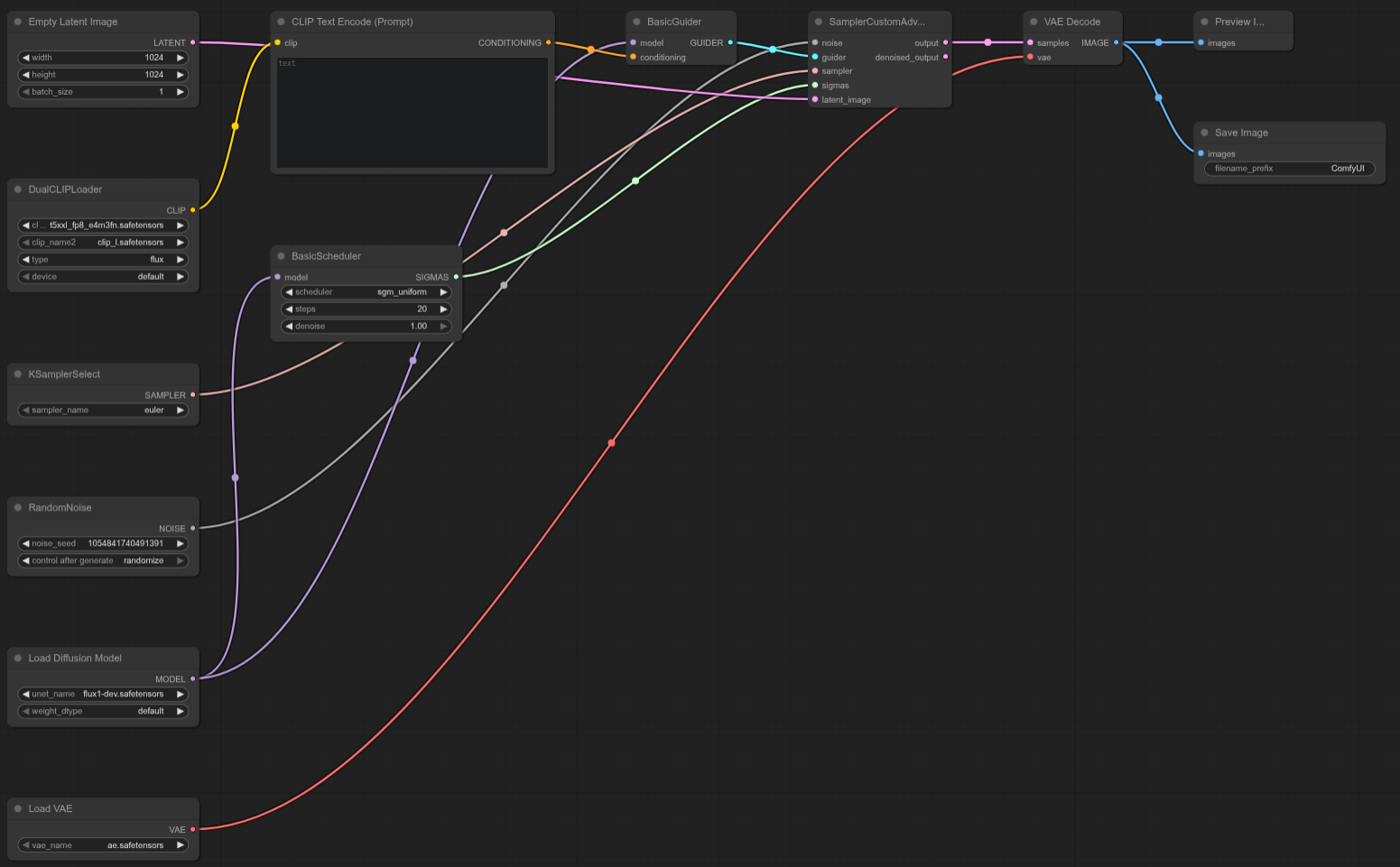
La RTX 5090 es aproximadamente un 37 % más rápida que la 4090 en esta prueba Flux Dev personalizada, que ofrece un fuerte impulso en el rendimiento para este flujo de trabajo específico.
WAN 2.2
Interfaz de usuario cómoda: Plantilla: video_wan2_2_14B_t2v (fp8 escalado + 4 pasos LoRA)
4090: 61,87 segundos
5090: 37,15 segundos
Aceleración = ~39,94%
Flujo de trabajo:
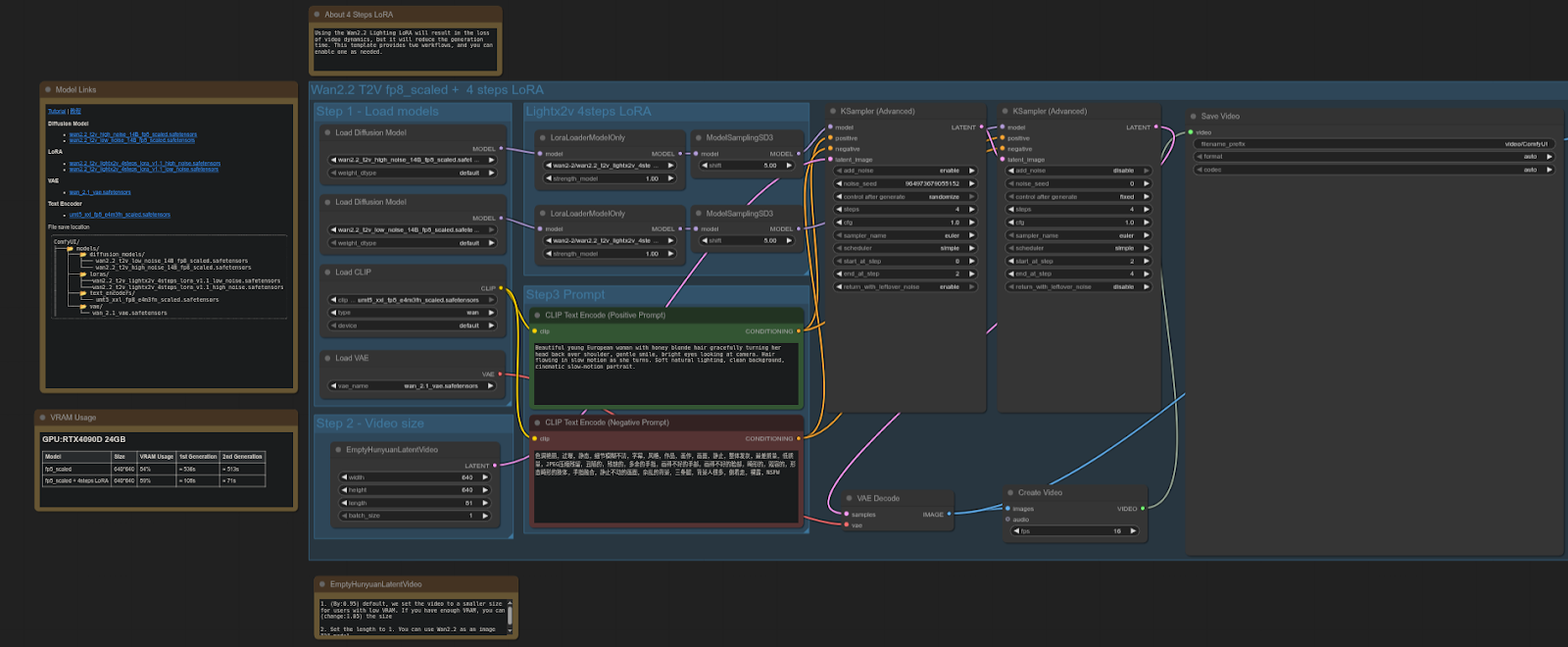
La RTX 5090 es aproximadamente un 40 % más rápida que la 4090 En esta prueba, se obtuvo una mejora significativa en el rendimiento de los flujos de trabajo de difusión de vídeo utilizando el modelo escalado FP8 + LoRA.
QWEN
Interfaz de usuario cómodaPlantilla: image_qwen_image_edit_2509
4090: 9,62 segundos
5090: 4,44 segundos
Aceleración = ~53,83%
Flujo de trabajo:
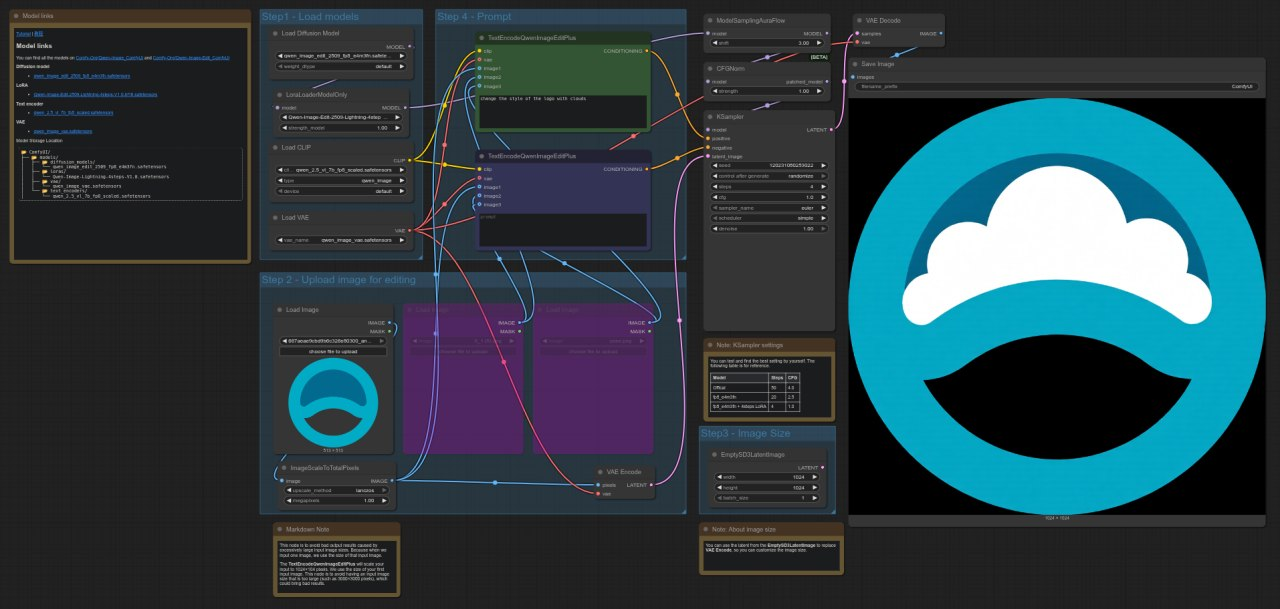
La RTX 5090 es aproximadamente un 54 % más rápida que la 4090 en esta prueba, se muestra una mejora notable en el rendimiento de los flujos de trabajo de edición de imágenes con el modelo Qwen.
Extra
Dado que el servidor está equipado con 2 GPU, es posible Distribuir programáticamente las cargas de trabajo entre ellos Esto se puede lograr definiendo DIFERENTE dispositivos para cada nodo, lo que permite realizar tareas dividido entre ambas GPUEl siguiente repositorio muestra cómo configurar ComfyUI para configuraciones multi-GPU mediante la asignación de nodos a diferentes dispositivos CUDA:
https://github.com/pollockjj/ComfyUI-MultiGPU

Breve introducción al protocolo Either
Anyone es una infraestructura global descentralizada para la privacidad. Al integrarse con su red de enrutamiento Onion, las aplicaciones pueden proporcionar privacidad sin necesidad de confianza y proteger su tráfico de red sin afectar la experiencia del usuario. La red consta de miles de nodos que aportan ancho de banda a cambio de recompensas en tokens. - https://www.anyone.io



.jpg)
.jpg)