.jpg)
Seiring kecerdasan buatan dan aplikasi berbasis AI terus berkembang setiap tahun, privasi internet menjadi semakin penting. Dengan mengintegrasikan teknologi privasi seperti Anyone Network - sebuah jaringan onion routing terdesentralisasi - pengguna dapat membangun di atas AI secara aman dan anonim.
Dalam blog post tamu ini dari tim Anyone Protocol, kita membahas bagaimana satu unit GPU cloud terdesentralisasi Aethir dapat dikonfigurasi untuk menyajikan konten secara anonim, serta mengevaluasi performanya dibandingkan penyedia GPU lainnya.
Mari kita mulai!
Ringkasan Eksekutif
Kolaborasi
Anyone bekerja sama dengan Aethir untuk mengevaluasi infrastruktur AI GPU cloud-nya, dengan fokus pada performa GPU dan skalabilitas. Cakupan review teknis ini berpusat pada benchmarking kemampuan GPU untuk workload AI, dilengkapi dengan pengembangan utility bot berbasis AI yang dijalankan di platform Telegram.
Sebelum menampilkan hasilnya, kita mulai dengan perbandingan kebutuhan infrastruktur SMB (small-to-medium business) dengan kapabilitas satu unit GPU cloud Aethir. Ini memberikan konteks untuk menilai efektivitas biaya, skalabilitas, dan performa dalam aplikasi AI nyata.
Arsitektur
Spesifikasi Cloud Server
- Model: RTX 5090×2
- CPU: AMD Ryzen 9 7900X 12-Core Processor
- RAM: 64 GiB
- Storage: 2TB
- Networking: 10Gb
- GPU Power: 575W
- OS: Ubuntu 22.04.1-Ubuntu
Spesifikasi On-Premise Server
- Model: RTX 4090
- CPU: 13th Gen Intel(R) Core(TM) i9-13900KS
- RAM: 64 GiB
- Storage: 2TB
- Networking: 1Gb
- GPU Power: 450W
- OS: Kernel 6.17.2-arch1-1
Arsitektur Software
Konfigurasi software antara cloud dan on-premise sama pada umumnya sama. Perbedaan utamanya ada pada GPU. Arsitektur benchmark didefinisikan sebagai berikut:
- Front end: Telegram Bot (user interface)
- Back end: python-telegram-bot terintegrasi dengan ComfyUI
- Database: PostgreSQL (state management dan pelacakan user-session)
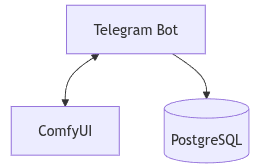
Alur Sistem
Interaksi pengguna dimulai di Telegram sebagai command interface. Setiap perintah diproses oleh bot dan diterjemahkan menjadi task untuk ComfyUI yang menjalankan inferensi di GPU.
Alurnya:
- Pengguna mengirim command di Telegram
- Bot menerima & mem-parsing command
- Bot mengirim task ke ComfyUI
- ComfyUI menjalankan inference dan menghasilkan output
- Output dikirim kembali ke pengguna melalui Telegram
- PostgreSQL mengelola session, job queue, dan mapping command (/f for flux) workflows
Struktur ini memungkinkan inference stateless dengan konteks persisten melalui database, membuatnya skalabel untuk single-user maupun multi-user.
Contoh Bot

Contoh bot command (/f for flux)
Command seperti /f (flux) akan mengirim prompt text-to-image ke ComfyUI. Bot memproses permintaan, menunggu gambar dihasilkan, lalu mengirimkannya kembali ke pengguna di Telegram.
Setelah gambar muncul (misalnya astronot atau t-shirt), pengguna dapat melanjutkan dengan perintah lain seperti “/qwen” untuk melakukan edit gambar, misalnya menambahkan t-shirt pada astronot:
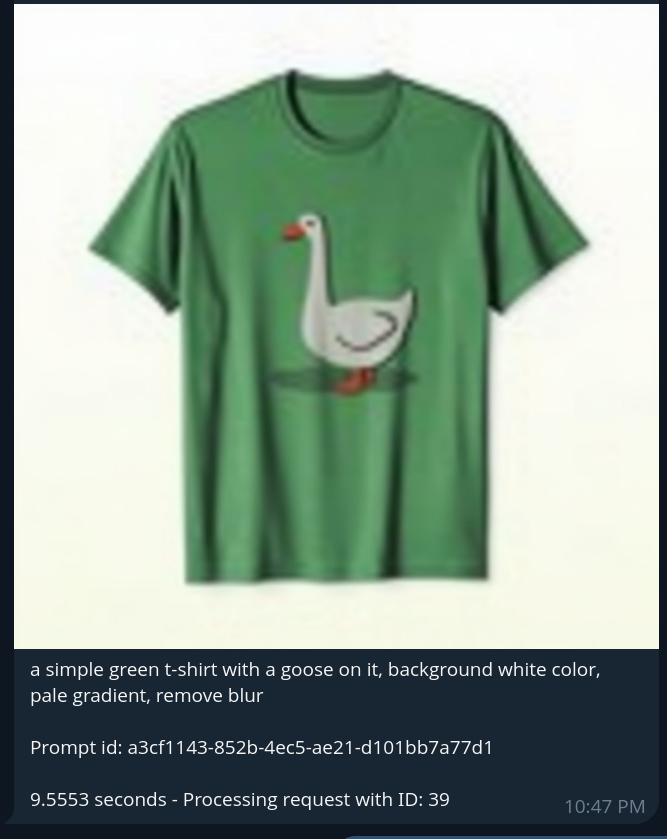

Ini memicu workflow model Qwen, yang melakukan image editing dengan menggunakan gambar sebelumnya sebagai input, dipadukan dengan instruksi teks. Gambar hasil akhirnya kemudian dikirim kembali melalui Telegram dengan modifikasi yang telah diterapkan (misalnya, astronaut yang sekarang mengenakan kaos bergambar angsa). Kemampuan command chaining ini memungkinkan proses pembuatan dan pengeditan gambar secara interaktif dan bertahap yang semuanya dari dalam antarmuka chat yang ringan.
Endpoints
Semua endpoint ComfyUI diekspos melalui routes sesuai dokumentasi resmi:
https://docs.comfy.org/development/comfyui-server/comms_routes
Endpoint-endpoint ini menjadi tulang punggung komunikasi antara back end dan ComfyUI, yang memungkinkan pengiriman prompt, manajemen queue yang cepat, upload dan download media, serta umpan balik secara real-time.
- /ws – websocket untuk komunikasi real-time
- /upload/image – upload gambar
- /prompt (GET) – melihat status queue
- /prompt (POST) – submit prompt
- /queue (GET) – status queue
- /queue (POST) – mengelola queue
Endpoint-endpoint ini diakses secara terprogram melalui back end, yang diorkestrasi oleh Telegram bot untuk menghadirkan pengalaman pengguna yang interaktif tanpa mengharuskan pengguna berinteraksi langsung dengan API.
Privasi
Untuk melindungi data pengguna, memastikan transmisi yang aman, dan menjaga privasi informasi, endpoint ComfyUI diarahkan melalui Anyone Network. Integrasi ini dimungkinkan dengan menggunakan Python SDK resmi yang disediakan di GitHub Anyone Protocol.
github.com/anyone-protocol/python-sdk
Dengan menggunakan development kit ini, kita dapat membungkus panggilan API ComfyUI di dalam tunnel yang aman dan anonim, sehingga permintaan pengguna serta media yang dihasilkan terlindungi dari akses atau eksposur yang tidak sah.
Arsitektur Anyone membungkus endpoint menggunakan binary bernama Anon:

Selain encrypted tunneling, Anyone SDK juga mendukung hidden services. Hidden services adalah endpoint server privat dan bersifat sementara yang dapat berjalan tanpa mengungkapkan lokasi, identitas, atau alamat IP. Fitur ini sangat berguna untuk kebutuhan yang memerlukan tingkat kerahasiaan tinggi, ketahanan terhadap sensor, atau keamanan yang lebih kuat. Bagi operator, hidden services memungkinkan tugas GPU dijalankan secara privat tanpa mengekspos detail infrastruktur. Baik saat mengonfigurasi inferensi pipeline secara anonim, berkolaborasi menggunakan data sensitif, atau sekadar bereksperimen tanpa meninggalkan jejak, hidden services membuka peluang baru untuk komputasi yang aman dan bersifat sovereign.
Contoh hidden service dapat terlihat seperti ini:
🌐 http://5ugakqk324gbzcsgql2opx67n5jisaqkc2mbglrodqprak5qz53mibyd.anon
🌐 http://5ugakqk324gbzcsgql2opx67n5jisaqkc2mbglrodqprak5qz53mibyd.anyone
Hidden services dapat dikonfigurasi untuk front end (misalnya jika platformnya adalah web), atau juga untuk endpoint back end ComfyUI, sehingga seluruh pipeline terlindungi.
Untuk informasi lebih lengkap mengenai hidden services, Anda dapat melihat dokumentasi Anyone:
https://docs.anyone.io/sdk-integrations/native-sdk/tutorials
Benchmark
Benchmark berikut membandingkan performa RTX 4090 dan RTX 5090 pada berbagai workflow dan model ComfyUI. Semua pengujian dilakukan menggunakan pengaturan dan template yang konsisten untuk memastikan perbandingan yang adil.
Stable Diffusion 3
ComfyUI Template: sd3.5_simple_example
4090: 8.96 detik (rata-rata)
5090: 5.96 detik (rata-rata)
Peningkatan Kecepatan = 33.48%
Workflow:
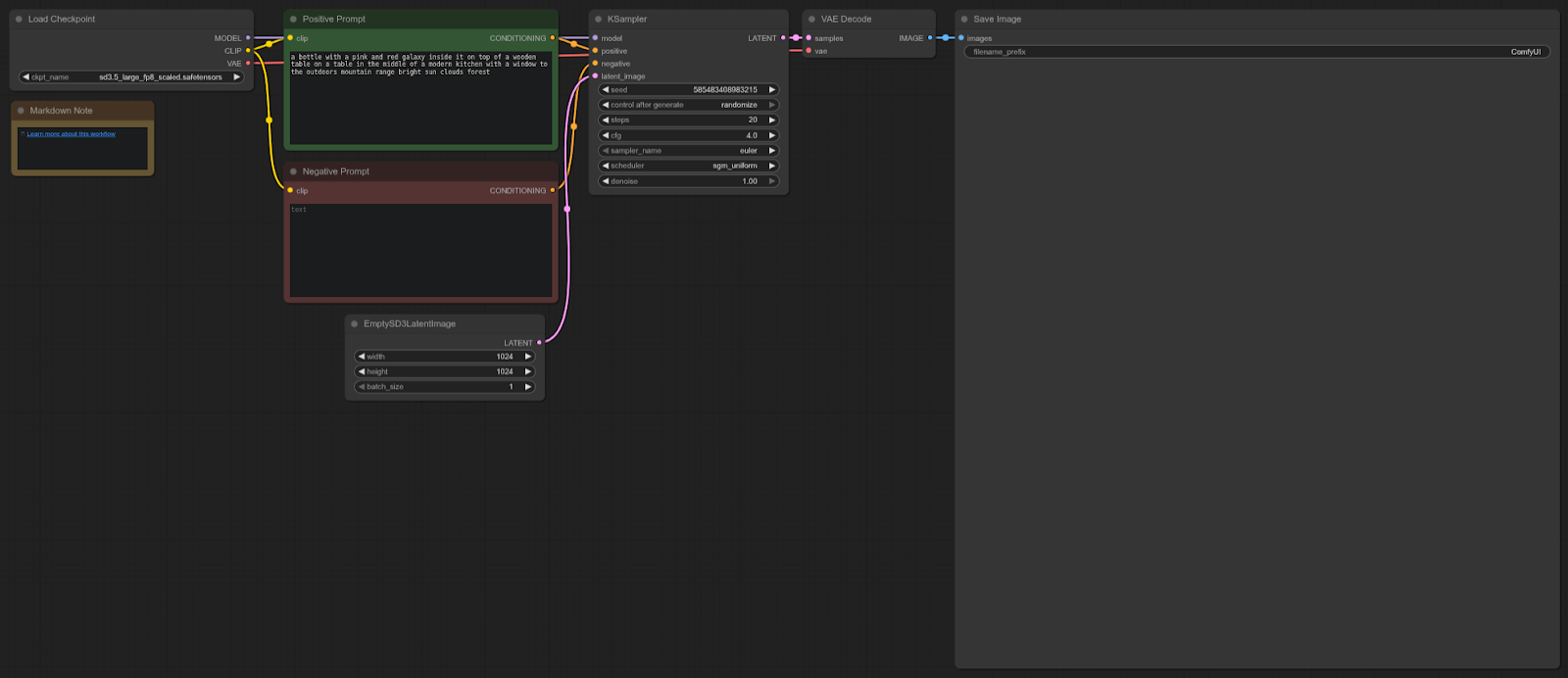
RTX 5090 sekitar 33% lebih cepat dibandingkan 4090 dalam pengujian ini, memberikan peningkatan performa yang solid untuk workflow Stable Diffusion 3.5 di ComfyUI.
FLUX-SCHNELL
ComfyUI Template: flux_schnell_full_text_to_image
4090: 4.92 detik
5090: 1.80 detik
Peningkatan Kecepatan = ~63.41%
Workflow:
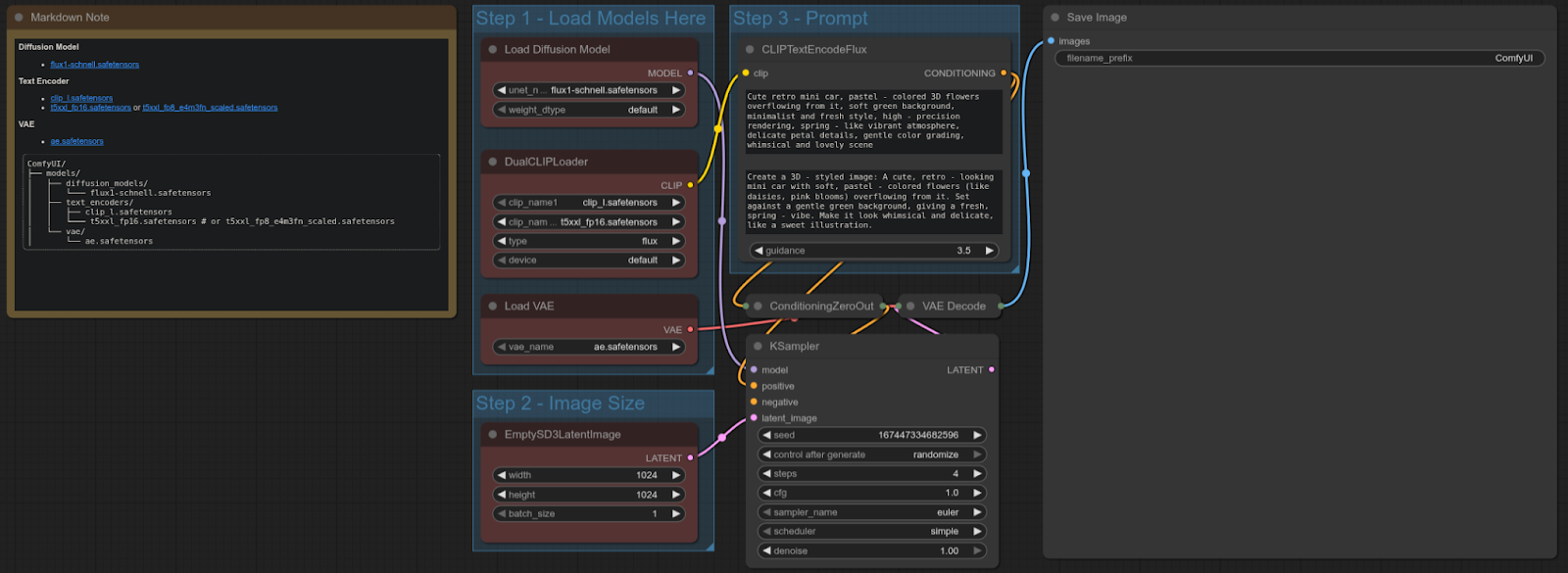
RTX 5090 sekitar 63% lebih cepat dibandingkan 4090 dalam pengujian ini, menghadirkan peningkatan performa signifikan untuk workflow text-to-image menggunakan model Flux Schnell.
FLUX-DEV
ComfyUI Template: N/A (Custom Flux Dev Test Template)
4090: 16.05 detik
5090: 10.11 detik
Peningkatan Kecepatan = ~37.01%
Workflow:
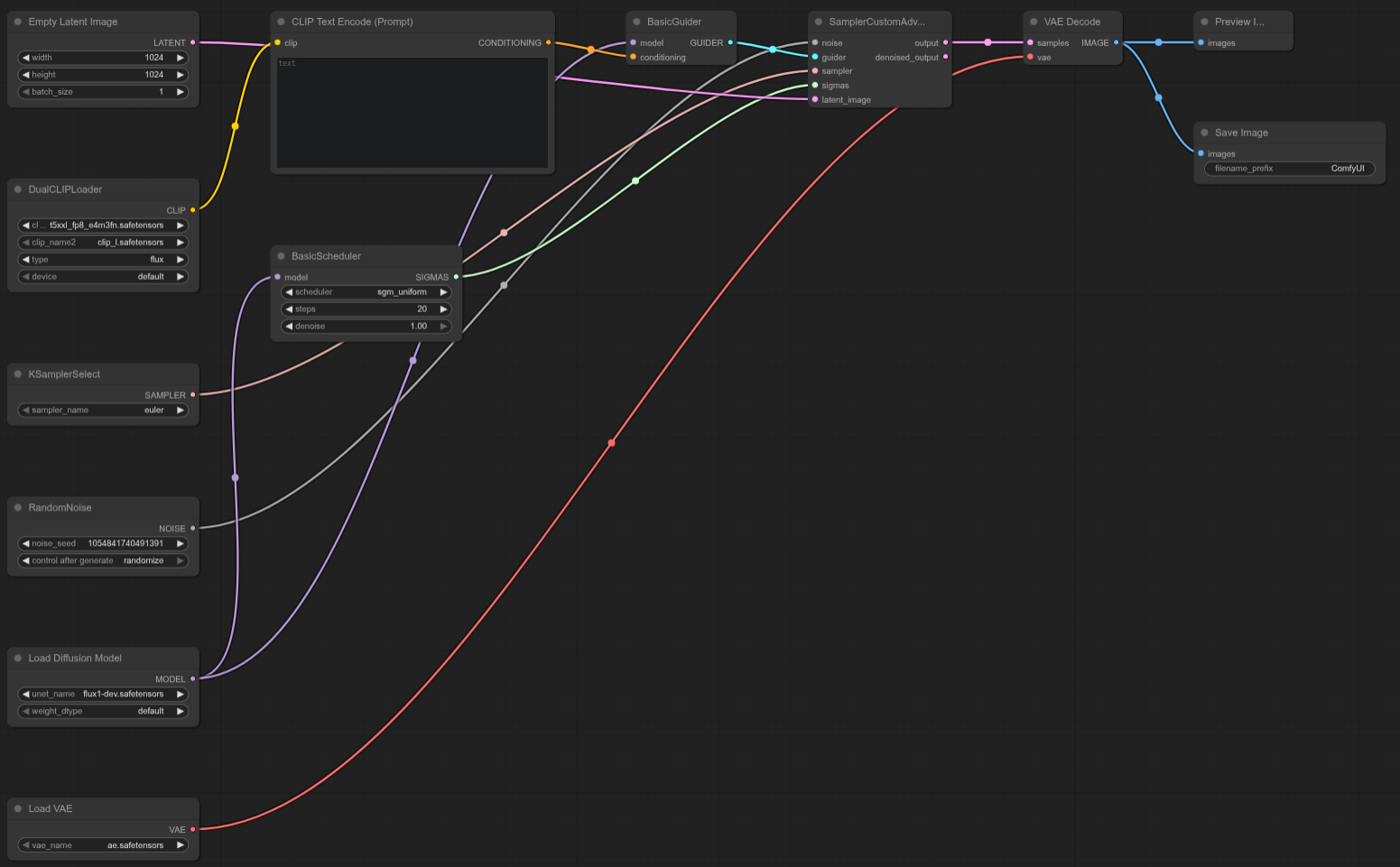
RTX 5090 sekitar 37% lebih cepat dibandingkan 4090 dalam uji Flux Dev kustom ini, memberikan peningkatan performa kuat untuk workflow spesifik tersebut.
WAN 2.2
ComfyUI Template: video_wan2_2_14B_t2v (fp8 scaled + 4 steps LoRA)
4090: 61.87 detik
5090: 37.15 detik
Peningkatan Kecepatan = ~39.94%
Workflow:
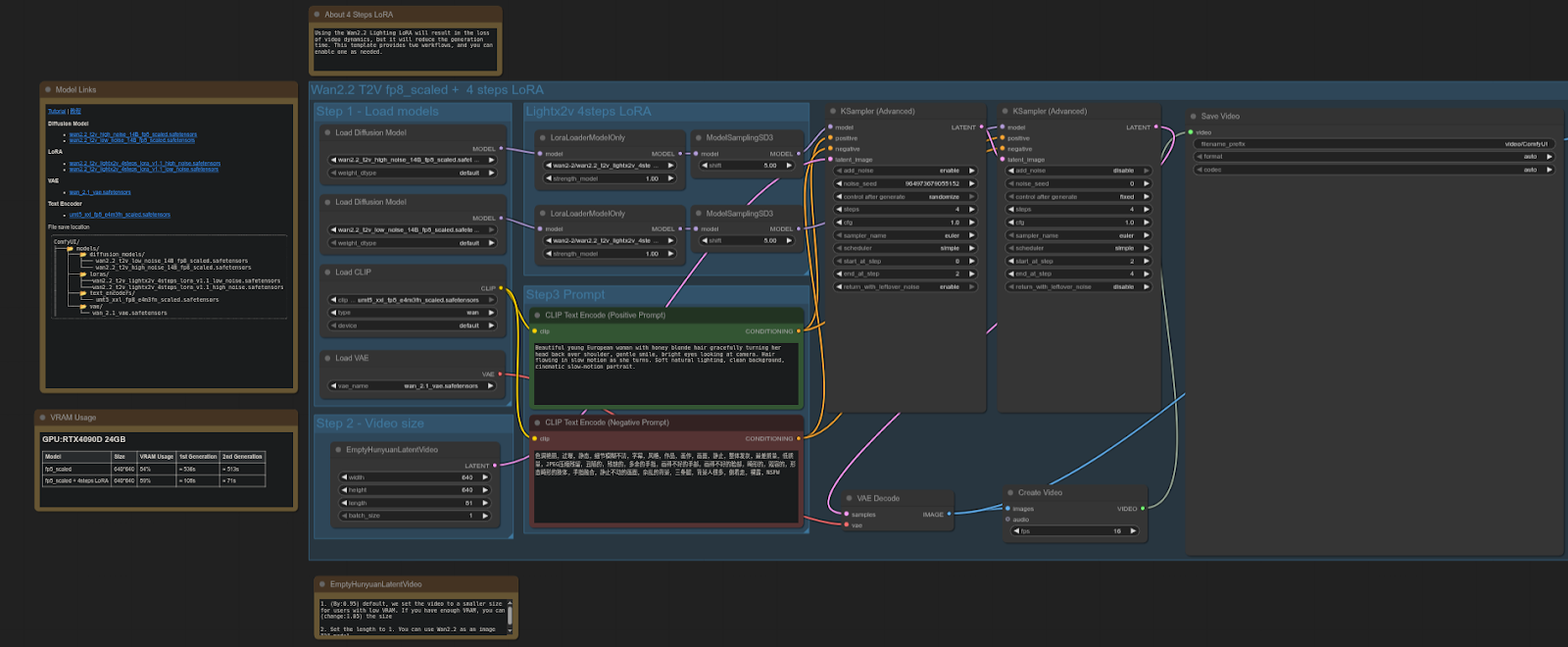
RTX 5090 sekitar 40% lebih cepat dibandingkan 4090 dalam pengujian ini, menghasilkan peningkatan performa signifikan untuk workflow video diffusion menggunakan model FP8 + LoRA.
QWEN
ComfyUI Template: image_qwen_image_edit_2509
4090: 9.62 detik
5090: 4.44 detik
Peningkatan Kecepatan = ~53.83%
Workflow:
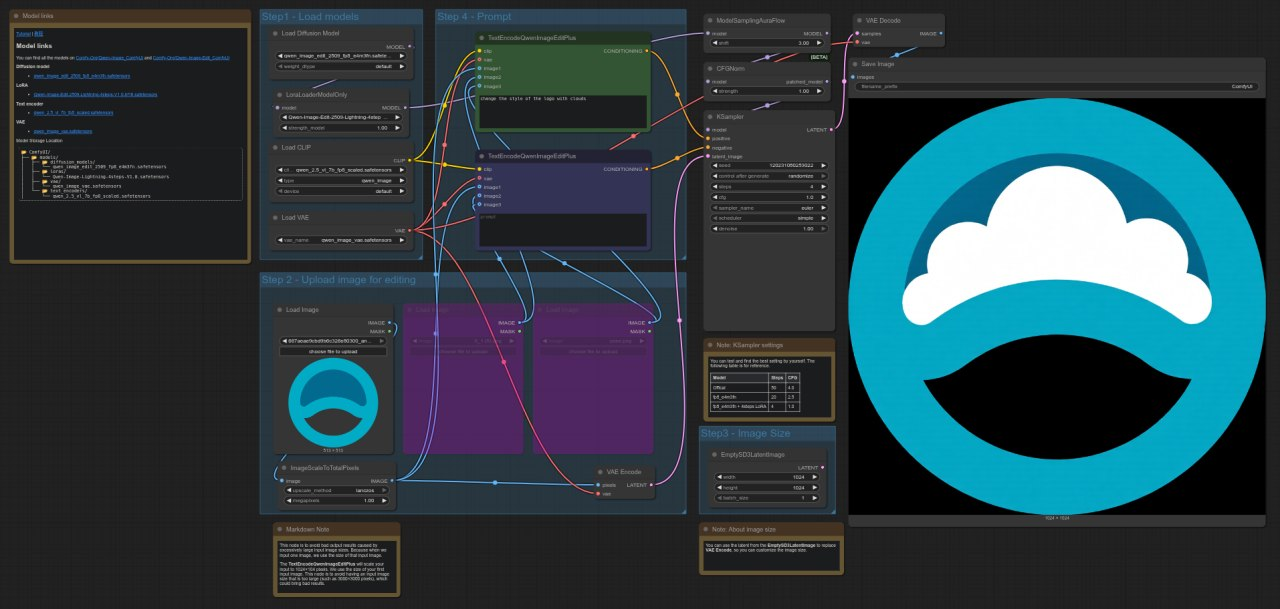
RTX 5090 sekitar 54% lebih cepat dibandingkan 4090 dalam pengujian ini, menunjukkan peningkatan performa yang menonjol untuk workflow penyuntingan gambar menggunakan model Qwen.
Extra
Karena server dilengkapi dengan 2 GPU, beban kerja dapat didistribusikan secara terprogram di antara keduanya. Hal ini dapat dilakukan dengan menetapkan perangkat CUDA tertentu untuk setiap node, sehingga tugas dapat dibagi ke kedua GPU tersebut. Repository berikut menunjukkan bagaimana cara mengonfigurasi ComfyUI untuk setup multi-GPU dengan menetapkan node ke perangkat CUDA yang berbeda:
https://github.com/pollockjj/ComfyUI-MultiGPU

Pengantar Singkat Anyone Protocol
Anyone adalah infrastruktur global terdesentralisasi untuk privasi. Dengan mengintegrasikan jaringan onion routing mereka, aplikasi dapat menyediakan privasi tanpa trust dan mengamankan trafik tanpa mengubah pengalaman pengguna. Ribuan node berkontribusi bandwidth dan mendapatkan reward token.
www.anyone.io



.jpg)
.jpg)