
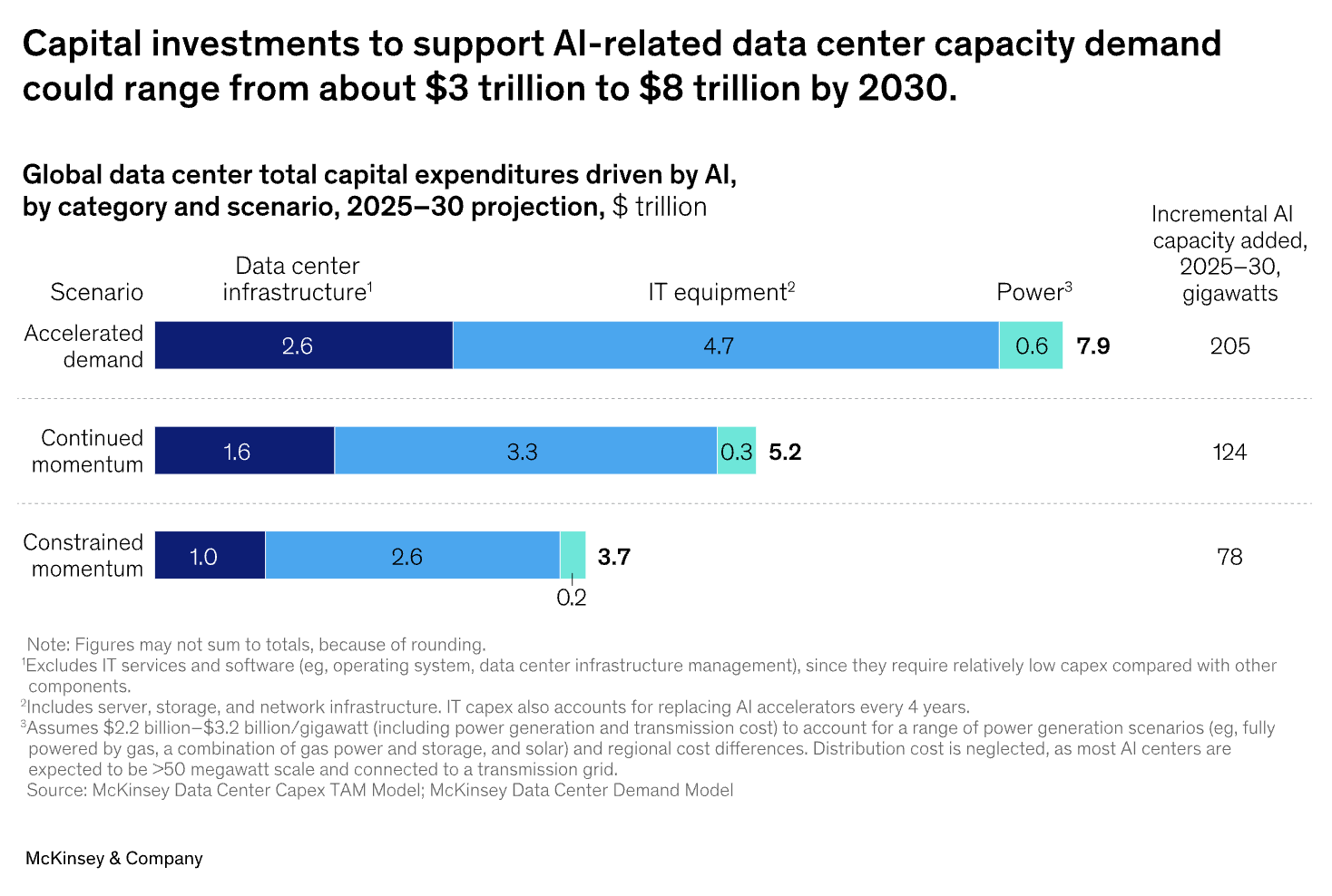
At NVIDIA GTC in Washington D.C., the announcement of a supercomputer deploying 100,000 Blackwell GPUs and the vision for "gigascale AI factories" sent a clear message: the era of monumental AI infrastructure is here. This scaling comes with a staggering price tag. According to McKinsey, the global demand for data center capacity is projected to require nearly $7 trillion in capital outlays by 2030, with the vast majority dedicated to AI workloads. This creates a central tension for organizations worldwide: how to harness the transformative power of AI without succumbing to the immense burden of capital expenditure (CapEx). The answer lies in a fundamental financial shift—from owning infrastructure to accessing it—through consumption-based GPU-as-a-Service (GPUaaS) models.
Aethir’s decentralized GPU cloud uses a globally distributed GPU-as-a-Service model that leverages 435,000+ premium GPU Containers for advanced, enterprise-grade AI and gaming workloads. With independent Cloud Hosts located in 93 countries and 200+ locations, Aethir’s DePIN stack provides unparalleled decentralized GPU cloud services, offering high scalability and cost-efficiency compared to expensive centralized clouds. More than 150 clients and partners already leverage Aethir’s distributed GPU-as-a-Service mode, showing how AI innovation can thrive on decentralized infrastructure.
Source: McKinsey
The Capital Expenditure Challenge in AI Infrastructure
The traditional approach to scaling AI has been a CapEx-intensive race to acquire and deploy as much hardware as possible. This model, however, is fraught with challenges. The multi-trillion-dollar investment forecast by McKinsey highlights the immense financial barrier to entry, creating what they term an "investment dilemma": overinvesting risks stranding expensive assets, while underinvesting means falling behind the competition.
In October 2024, leaders from OpenAI and Microsoft publicly admitted that AI compute demand was outstripping their available capacity. The issue is compounded by hidden costs that extend far beyond the initial GPU purchase. High-speed networking, advanced cooling systems, massive power infrastructure, and ongoing maintenance all contribute to a Total Cost of Ownership (TCO) that can dwarf the initial hardware investment. Furthermore, studies have shown that more than half of all existing GPU capacity lies idle at any given time, representing a massive and inefficient use of capital.
The OpEx Advantage: How GPU-as-a-Service Transforms AI Economics
GPU-as-a-Service flips the script by converting the massive upfront CapEx of hardware acquisition into a flexible, predictable operational expenditure (OpEx). Instead of owning, organizations pay for what they use, when they use it. This model offers a suite of strategic advantages that are reshaping the economics of AI.
The market has validated this shift in resounding fashion. The GPUaaS industry, valued at $3.23 billion in 2023, is projected to explode to nearly $50 billion by 2032, signaling a definitive move toward consumption-based models.
NVIDIA GTC 2025: Signaling the Infrastructure Inflection Point
NVIDIA's GTC announcements served as a powerful signal of this industry inflection point. CEO Jensen Huang's vision of "gigascale AI factories" and his statement that "AI infrastructure is an ecosystem-scale challenge requiring hundreds of companies to collaborate" underscores the immense complexity of modern AI deployments. The sheer scale of deploying over 100,000 GPUs in a single system makes traditional ownership models increasingly impractical for all but a handful of global hyperscalers.
The emphasis on partnerships, between government, enterprise, and cloud providers like the DOE, Oracle, and Uber, further highlights a move away from monolithic, self-owned data centers. The future of AI infrastructure is about a distributed, interconnected, and flexible ecosystem where consumption-based models thrive, providing the necessary agility to participate in this collaborative future.
The Strategic Shift: Why OpEx Models Are Winning
The move to OpEx is more than just a financial maneuver; it is a strategic imperative. Industry leaders highlighted the growing importance of flexible financial solutions like "Cooling-as-a-Service" and "Energy-as-a-Service" to shift CapEx to OpEx budgets while meeting critical business metrics. This approach allows companies to focus on their core competency, developing innovative AI applications, rather than becoming data center operators.
This strategic shift is also driven by efficiency and sustainability. By leveraging the existing, often underutilized, global pool of GPU resources, distributed GPUaaS platforms like Aethir reduce the need to build new, energy-intensive data centers. This not only lowers the carbon footprint of AI development but also mitigates the risk of technology obsolescence in a field where new hardware is released at a breakneck pace. Ultimately, the OpEx model democratizes access to enterprise-grade AI infrastructure, enabling innovation from startups and researchers who were previously priced out of the market.
The Future is Flexible
The challenge of scaling AI in the modern era is, at its core, a financial architecture problem. The CapEx-heavy models of the past are ill-suited for a landscape defined by rapid innovation, uncertain demand, and unprecedented scale. The future belongs to those who can remain agile, and financial flexibility is paramount.
Operational expenditure models, delivered through GPU-as-a-Service platforms like Aethir's distributed cloud infrastructure, provide the critical solution, allowing organizations to tap into immense computational power without the anchor of massive upfront investment. As the AI race intensifies, the ability to scale efficiently and intelligently will be the key differentiator. In this new paradigm, financial agility is not just an advantage—it is as crucial as the computational power itself.
Ready to gain the financial agility your AI scaling demands? Contact Aethir to explore how our decentralized GPU cloud delivers enterprise-grade compute power through flexible, OpEx-based infrastructure.




