
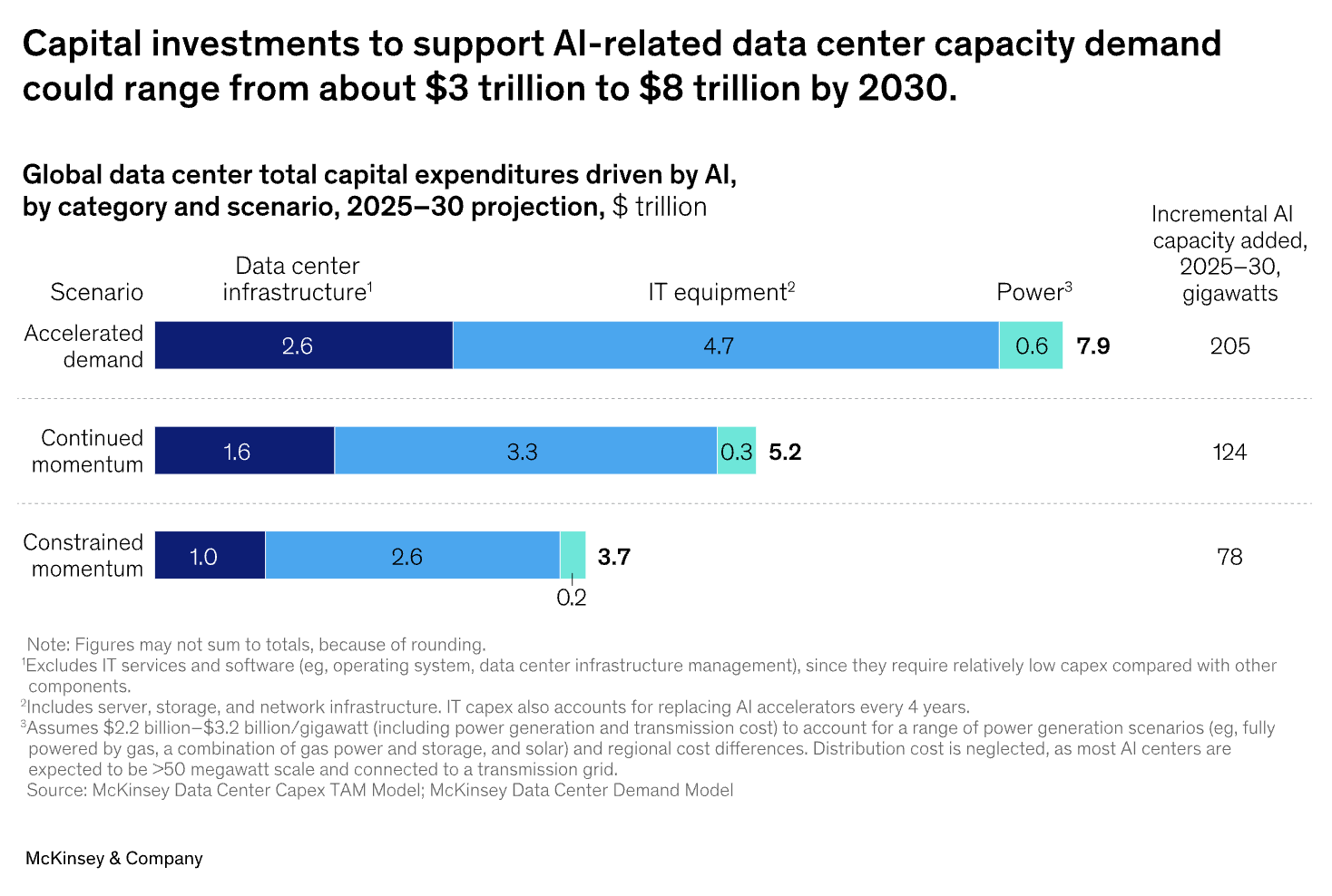
На конференции NVIDIA GTC в Вашингтоне было объявлено о создании суперкомпьютера с 100 000 GPU Blackwell и представлено видение «гига-масштабных ИИ-фабрик» — четкий сигнал: эра колоссальной инфраструктуры для искусственного интеллекта уже наступила. Однако этот масштаб сопровождается ошеломляющей стоимостью. Согласно данным McKinsey, глобальный спрос на мощности дата-центров к 2030 году потребует почти 7 триллионов долларов капитальных вложений, причем подавляющая часть будет направлена на ИИ-нагрузки. Это создает ключевое противоречие для организаций по всему миру: как использовать преобразующую силу ИИ, не поддаваясь тяжкому бремени капитальных затрат (CapEx). Ответ заключается в фундаментальном финансовом сдвиге — от владения инфраструктурой к доступу к ней — через модели, основанные на потреблении, такие как GPU-as-a-Service (GPUaaS).
Децентрализованное GPU-облако Aethir использует глобально распределённую модель GPU-as-a-Service, задействуя более 435 000+ премиальных GPU-контейнеров для продвинутых корпоративных и игровых ИИ-нагрузок. Благодаря независимым облачным хостам в 93 странах и более чем 200 локациях, децентрализованный стек Aethir (DePIN) предоставляет беспрецедентные облачные GPU-сервисы, обеспечивая высокую масштабируемость и экономическую эффективность по сравнению с дорогими централизованными облаками. Более 150 клиентов и партнёров уже используют распределённую модель GPU-as-a-Service от Aethir, демонстрируя, как инновации в ИИ могут развиваться на децентрализованной инфраструктуре.
Источник: McKinsey
Проблема капитальных затрат в инфраструктуре ИИ
Традиционный подход к масштабированию ИИ основан на модели, требующей огромных CapEx — гонке за приобретением и развёртыванием как можно большего количества оборудования. Однако у этого подхода множество проблем. Прогноз многотриллионных инвестиций, опубликованный McKinsey, подчёркивает колоссальный финансовый барьер для входа, создавая так называемую «инвестиционную дилемму»: чрезмерные вложения приводят к замораживанию дорогих активов, а недостаточные — к отставанию от конкурентов.
В октябре 2024 года руководители OpenAI и Microsoft публично признали, что спрос на вычислительные мощности для ИИ превышает их текущие возможности. Проблему усугубляют скрытые расходы, значительно выходящие за рамки первоначальной покупки GPU: это высокоскоростные сети, системы охлаждения, инфраструктура электропитания и постоянное обслуживание, формирующие совокупную стоимость владения (TCO), которая может значительно превысить стоимость самого оборудования. Более того, исследования показали, что более половины существующих GPU остаются неиспользованными в любой момент времени, что представляет собой неэффективное использование капитала.
Преимущество OpEx: как GPU-as-a-Service меняет экономику ИИ
Модель GPU-as-a-Service полностью меняет правила игры, превращая огромные капитальные затраты на оборудование (CapEx) в гибкие и предсказуемые операционные расходы (OpEx). Вместо владения компании платят только за фактически используемые ресурсы. Эта модель предоставляет ряд стратегических преимуществ, меняющих экономику ИИ.
Рынок однозначно подтвердил этот сдвиг: индустрия GPUaaS, оценённая в 3,23 млрд долларов в 2023 году, к 2032 году прогнозируется на уровне почти 50 млрд долларов, что свидетельствует о переходе к моделям, основанным на потреблении.
NVIDIA GTC 2025: сигнал к инфраструктурному перелому
Объявления на NVIDIA GTC 2025 стали мощным сигналом о переломном моменте в индустрии. Видение генерального директора Дженсена Хуана о «гига-масштабных фабриках ИИ» и его утверждение, что «инфраструктура ИИ — это вызов масштаба экосистемы, требующий сотрудничества сотен компаний», подчёркивают огромную сложность современных ИИ-развёртываний. Масштаб систем с более чем 100 000 GPU делает традиционные модели владения всё менее жизнеспособными, за исключением нескольких глобальных гипермасштабных игроков.
Акцент на партнёрства между государственными структурами, корпорациями и облачными провайдерами (например, DOE, Oracle, Uber) подчёркивает уход от монолитных дата-центров к распределённой, взаимосвязанной и гибкой экосистеме, где модели, основанные на потреблении, становятся нормой, обеспечивая необходимую подвижность для участия в этом совместном будущем.
Стратегический сдвиг: почему модели OpEx побеждают
Переход к OpEx — это не просто финансовая манипуляция, а стратегическая необходимость. Лидеры отрасли подчёркивают растущую роль гибких финансовых решений, таких как «Cooling-as-a-Service» и «Energy-as-a-Service», которые переводят CapEx в OpEx, сохраняя при этом ключевые бизнес-показатели. Этот подход позволяет компаниям сосредоточиться на основном — разработке инновационных ИИ-приложений — вместо того, чтобы становиться операторами дата-центров.
Стратегический сдвиг также продиктован эффективностью и устойчивостью. Используя уже существующий, часто неиспользуемый глобальный пул GPU-ресурсов, распределённые платформы GPUaaS, такие как Aethir, снижают необходимость в строительстве новых энергоёмких дата-центров. Это не только уменьшает углеродный след разработки ИИ, но и снижает риск устаревания технологий в условиях стремительного выхода нового оборудования. В итоге модель OpEx демократизирует доступ к корпоративной инфраструктуре ИИ, открывая возможности для стартапов и исследователей, ранее лишённых ресурсов.
Будущее за гибкостью
Проблема масштабирования ИИ в современную эпоху — в своей сути проблема финансовой архитектуры. CapEx-модели прошлого не подходят для среды, где доминируют быстрые инновации, неопределённый спрос и беспрецедентные масштабы. Будущее принадлежит тем, кто способен оставаться гибким, а финансовая адаптивность становится ключевым фактором.
Модели операционных расходов, реализованные через GPU-as-a-Service-платформы, такие как распределённая облачная инфраструктура Aethir, предоставляют необходимое решение, позволяя организациям использовать огромную вычислительную мощность без тяжёлого груза капитальных затрат. По мере того как гонка ИИ усиливается, способность масштабироваться эффективно и разумно станет решающим преимуществом. В этой новой парадигме финансовая гибкость столь же важна, как и вычислительная мощность.
Готовы обрести финансовую гибкость, необходимую для масштабирования вашего ИИ? Свяжитесь с Aethir, чтобы узнать, как наше децентрализованное GPU-облако предоставляет вычислительные мощности корпоративного уровня через гибкую инфраструктуру, основанную на модели OpEx.




