
Key Takeaways:
- TSMC confirms AI is a multi-year megatrend that will continue to grow rapidly, supercharging AI compute demand.
- Scaling GPU production isn’t enough if the GPUs aren’t readily available for AI workloads.
- Aethir’s decentralized GPU cloud offers a viable alternative for cost-efficient, scalable access to AI infrastructure.
TSMC, the leading global chipmaker for advanced, high-performance GPUs used for AI workloads, confirms in its latest revenue report that AI demand is durable for years as a global megatrend. The AI industry is here to stay, and it needs scalable, cost-efficient computing to grow and evolve. The technology for visionary AI innovations already exists, but AI compute demand is constrained by compute bottlenecks. Aethir’s distributed AI infrastructure complements TSMC’s claims of AI’s future growth by providing a decentralized GPU cloud alternative to traditional GPU provision models.
When TSMC speaks with confidence about the future of AI demand, it sends a clear message to the entire AI industry. Demand will continue to grow, but AI innovators and enterprises looking to integrate AI functionalities into their business models need efficient access to AI inference infrastructure.
TSMC reported a 35% year-on-year jump in fourth-quarter net profit for the world’s largest contract chipmaker, amounting to roughly $16 billion. Company executives and market observers attribute the strength to surging orders tied to artificial intelligence and high-performance computing (HPC). Industry reporting indicates that AI and HPC now account for about 55% of sales. Chips manufactured at 7-nanometer or smaller accounted for approximately 77% of wafer revenue in the quarter, up from 69% a year earlier.
These numbers indicate the rapidly growing appetite of chip buyers for advanced technology to power extremely compute-intensive data centers, AI accelerators, and next-generation servers. AI compute demand is surging, and TSMC’s multi-year vision of AI infrastructure demand growth implies long-term planning.
For AI companies, startups, and developers, this means that the risk is supply, not demand. That’s precisely what compute providers need to address, and Aethir’s decentralized GPU cloud is leading the way with its distributed AI infrastructure as a solution.
CapEx Tells the Real Story: Supply Tightness Is Not Easing
Although massive, billion-dollar investments are pouring into the AI infrastructure sector, they aren’t solving the compute bottleneck due to standardized GPU supply chain constraints. That’s because significant investments don’t necessarily yield quick relief for the growing demand for premium AI inference infrastructure. Significant CapEx investments are viable for the leading players, but smaller AI companies, startups, and indie developer teams can’t afford to invest millions in AI infrastructure.
While TSMC’s record-level CapEx shows the company is preparing for years of soaring AI compute demand, access to GPUs powered by TSMC’s chips is quite limited due to compute bottlenecks. Big tech cloud providers like Google Cloud, Azure, and AWS are purchasing thousands of high-performance GPUs, subject to strict client contracts, vendor lock-in risks, and unpredictable pricing. Centralized clouds are prone to complex GPU supply chain cycles, defined by massive CapEx and months or years-long expansions that involve building new regional data centers.
The flourishing AI sector can’t wait that long. It needs compute now, and for smaller enterprises in need of AI infrastructure, big-tech clouds are creating a supply chain bottleneck that slows down AI innovation.
Furthermore, the long supply chain cycles required to support aggressive investments can’t keep pace with the AI growth curve. If computing isn’t instantly available, once it becomes available, the AI sector will already need more GPUs. This endless loop of chasing AI infrastructure demand while supply remains insufficient can only be broken by adopting a decentralized GPU cloud model. Chip production growth isn’t sufficient if it doesn’t translate into faster availability for clients.
The Bottleneck Has Moved: From Chips to Usable Compute
Ramping up AI infrastructure production is an absolute necessity, but it isn’t enough to just produce GPUs if the AI industry can’t access them flexibly and scalably. This creates a supply bottleneck even when GPUs are present in the production pipeline, because they sit idle rather than processing AI workloads such as LLM training, AI agent training, and other inference tasks.
Accessing effective compute is the key issue for AI’s global evolution, meaning deployable AI capacity isn’t the same as raw chip supply.
Centralized hyperscaler clouds suffer from:
- Long onboarding queues
- Geographic concentration
- Underutilized GPU fleets
- Rigid contracts mismatched to inference-heavy workloads.
Utilization and GPU availability for AI workloads matter far more than just GPU numbers. Centralized cloud models can’t efficiently service the AI sector, often having GPU utilization rates below 60-70%. This means existing GPUs aren’t fully utilized, leading to higher service and maintenance costs.
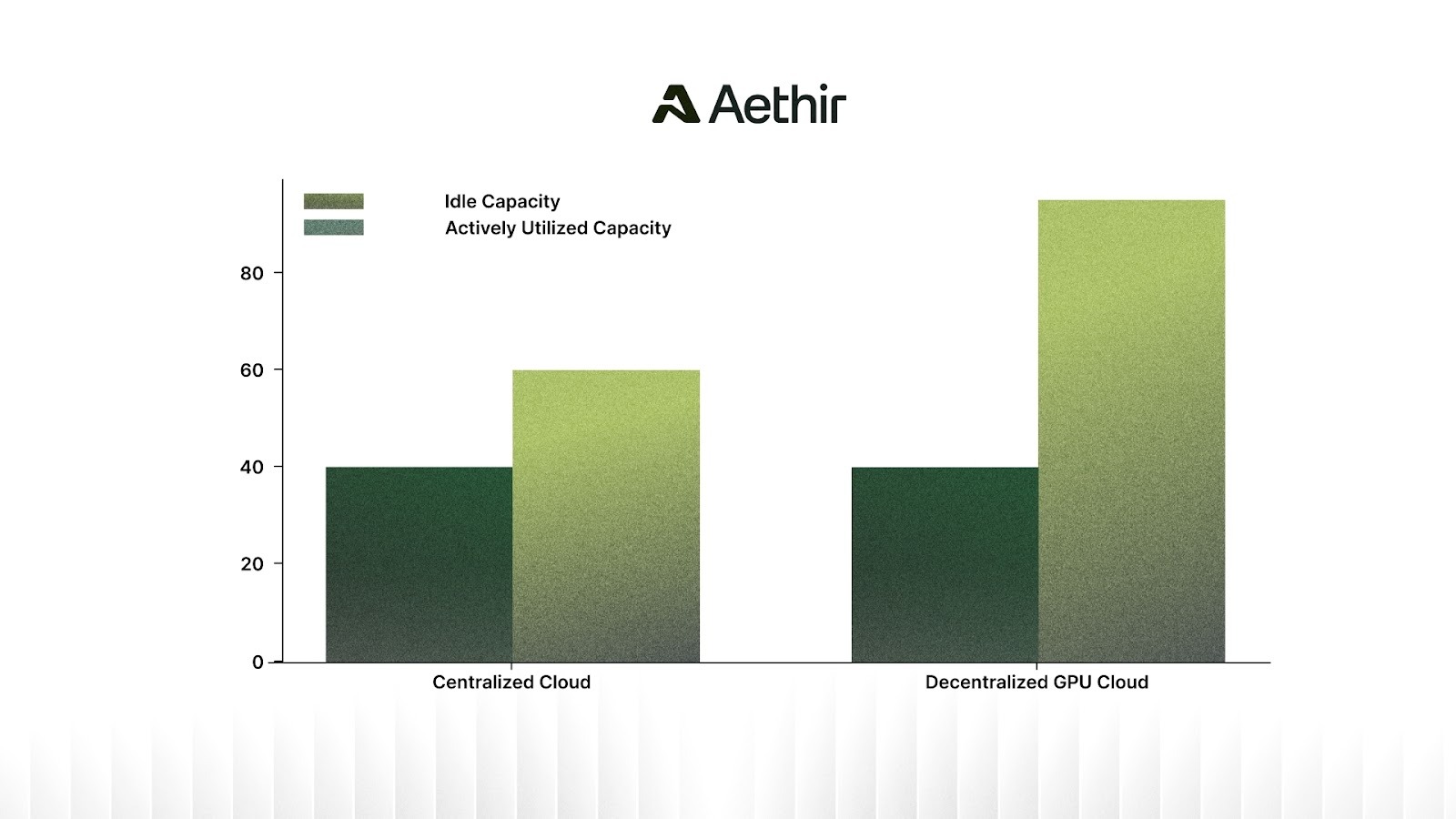
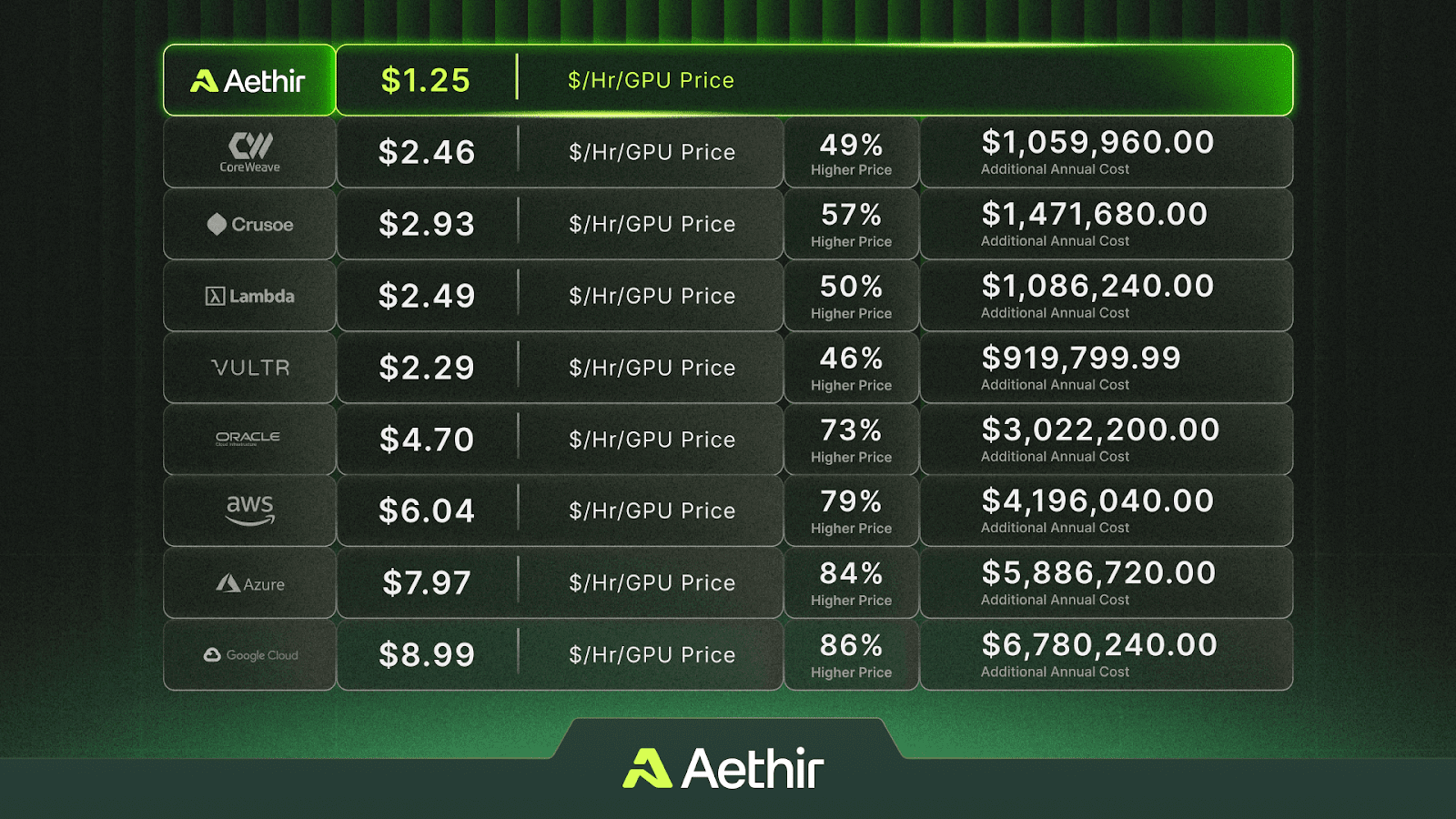
Aethir’s decentralized GPU cloud, on the other hand, has an average GPU utilization rate of 95%+, allowing us to offer up to 86% lower prices for NVIDIA H100s than Google Cloud.
Aethir’s Decentralized GPU Cloud: The Layer Above Silicon
TSMC is the leading global manufacturer for NVIDIA’s high-performance GPUs, providing a foundation for AI compute infrastructure. However, centralized cloud providers can’t efficiently channel that foundation’s hardware capabilities to AI enterprises, developers, and startups on a global scale.
Aethir’s distributed AI infrastructure model flips the script on centralized compute bottlenecks by operating a decentralized GPU cloud spanning 94 countries, 200+ locations, and nearly 440,000 top-shelf GPU containers. Our AI inference infrastructure includes thousands of NVIDIA H100s, H200s, B200s, and other leading, high-performance chips specifically designed for advanced AI workloads.
The Aethir network connects numerous, autonomous compute providers, also referred to as Cloud Hosts, who provide GPU compute and earn ATH tokens in return. We already have 150+ clients and partners trusting Aethir’s AI inference infrastructure in their daily operations, demonstrating the effectiveness and user confidence in our decentralized GPU-as-a-Service network.
The four pillars of Aethir’s AI inference infrastructure:
- Access: Alternative path to production-grade GPUs when centralized supply is saturated.
- Utilization: Decentralized architecture designed to keep GPUs working, not idle.
- Distribution: Global compute routing aligns with inference-driven, latency-sensitive AI workloads.
- Resilience: Reduced dependency on single jurisdictions or cloud compute bottlenecks.
These characteristics make Aethir a trustworthy alternative to centralized clouds, capable of circumventing GPU supply constraints while maximizing AI compute utilization. Aethir’s decentralized GPU cloud is constantly expanding and onboarding new cohorts of Cloud Hosts into our distributed AI infrastructure network, in line with growing AI compute demand.
We have the means to ensure GPU availability for AI workloads, enabling the shipment of AI products without delays caused by centralized cloud compute bottlenecks.
The 2026 - 2029 AI Infrastructure Potential
As AI compute demand continues to grow and industry leaders like TSMC and NVIDIA remain dedicated to compute innovation, GPU access is becoming the primary AI compute bottleneck. This makes compute a strategic asset essential for powering today's AI workloads and building the innovations of the future.
To efficiently support the rapidly growing AI compute demand, companies need to secure GPU availability for AI workloads without dependency on centralized cloud bottlenecks. Unlike traditional cloud providers, which charge hefty service fees, depend on multi-month GPU procurement cycles, and impose strict contracts with vendor lock-in risks, Aethir offers a distributed AI infrastructure alternative.
A decentralized GPU cloud architecture is an essential infrastructure model for the stable growth of the AI industry. Aethir’s GPU-as-a-Service is positioned to support the future growth in AI demand through our distributed network of high-performance GPUs on a global scale.
Explore Aethir’s enterprise AI GPU offering here.
Learn more about Aethir’s decentralized GPU cloud in our official blog section.
FAQs
Why does TSMC’s latest update matter for the AI industry?
TSMC confirms AI is a multi-year megatrend with strong revenue visibility, signaling that AI demand is durable and long-term, not cyclical or experimental.
If GPU production is increasing, why is AI compute still scarce?
Scaling GPU manufacturing doesn’t guarantee availability because long supply chains, centralized clouds, and underutilized fleets prevent GPUs from reaching AI workloads efficiently.
Why is compute availability now a bigger risk than AI demand?
AI demand is accelerating faster than infrastructure can be provisioned, making access to usable, deployable compute the primary constraint for AI builders and enterprises.
How does Aethir help solve the AI compute bottleneck?
Aethir provides a decentralized GPU cloud with 95%+ utilization, global distribution, and cost-efficient access to production-grade AI infrastructure.




